Execução Projetos MLflow em Databricks
Aviso
O MLflow Projects não é mais suportado.
Um projeto MLflow é um formato para empacotar código de ciência de dados de maneira reutilizável e reproduzível. O componente MLflow Projects inclui uma API e ferramentas de linha de comando para execução de projetos, que também se integram ao componente de acompanhamento para registrar automaticamente os parâmetros e git commit do seu código-fonte para reprodutibilidade.
Este artigo descreve o formato de um projeto MLflow e como executar um projeto MLflow remotamente em clusters Databricks usando a CLI MLflow, que facilita escalar verticalmente seu código de ciência de dados.
Formato de projeto MLflow
Qualquer diretório local ou repositório Git pode ser tratado como um projeto MLflow. As seguintes convenções definem um projeto:
O nome do projeto é o nome do diretório.
O ambiente de software é especificado em
python_env.yaml, se presente. Se nenhum arquivopython_env.yamlestiver presente, o MLflow usará um ambiente virtualenv contendo apenas Python (especificamente, o Python mais recente disponível para virtualenv) ao executar o projeto.Qualquer arquivo
.pyou.shno projeto pode ser um ponto de entrada, sem parâmetros explicitamente declarados. Ao executar tal comando com um conjunto de parâmetros, o MLflow passa cada parâmetro na linha de comando usando a sintaxe--key <value>.
Você especifica mais opções adicionando um arquivo MLproject, que é um arquivo de texto na sintaxe YAML. Um exemplo de arquivo MLproject tem a seguinte aparência:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
Para Databricks Runtime 13.0 ML e acima, MLflow Os projetos não podem ser executados com sucesso em um Databricks Job tipo cluster. Para migrar os projetos MLflow existentes para Databricks Runtime 13.0 ML e acima, consulte MLflow Databricks Spark Job formato de projeto.
MLflow Databricks Spark Job formato do projeto
MLflow Databricks Spark O projeto de trabalho é um tipo de projeto MLflow introduzido em MLflow 2.14. Esse tipo de projeto oferece suporte à execução de projetos do MLflow em um cluster do Spark Jobs e só pode ser executado usando o backend databricks.
Databricks Spark Os projetos de trabalho devem definir databricks_spark_job.python_file ou entry_points. A não especificação de uma das configurações ou a especificação de ambas gera uma exceção.
O exemplo a seguir é de um arquivo MLproject que usa a configuração databricks_spark_job.python_file. Essa configuração envolve o uso de um caminho codificado para o arquivo de execução do Python e seus argumentos.
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
O exemplo a seguir é de um arquivo MLproject que usa a configuração entry_points:
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: {type: string, default: model}
script_name: {type: string, default: train.py}
command: "python {script_name} {model_name}"
A configuração entry_points permite que o senhor passe parâmetros que estejam usando parâmetros de linha de comando, como:
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
As seguintes limitações se aplicam aos projetos do Databricks Spark Job:
Esse tipo de projeto não é compatível com a especificação das seguintes seções no arquivo
MLproject:docker_env,python_envouconda_env.As dependências do seu projeto devem ser especificadas no campo
python_librariesda seçãodatabricks_spark_job. As versões do Python não podem ser personalizadas com esse tipo de projeto.O ambiente de execução deve usar o ambiente principal de tempo de execução do driver Spark para execução no Job clusters que usa o Databricks Runtime 13.0 ou superior.
Da mesma forma, todas as dependências do Python definidas como necessárias para o projeto devem ser instaladas como dependências do cluster do Databricks. Esse comportamento é diferente dos comportamentos anteriores de execução de projetos em que a biblioteca precisava ser instalada em um ambiente separado.
execução de um projeto MLflow
Para executar um projeto MLflow em clusters Databricks no workspace default, use o comando:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
onde <uri> é um URI de repositório Git ou pasta contendo um projeto MLflow e <json-new-cluster-spec> é um documento JSON contendo uma estrutura new_cluster. O URI do Git deve estar no formato: https://github.com/<repo>#<project-folder>.
Um exemplo de especificação clusters é:
{
"spark_version": "7.5.x-scala2.12",
"num_workers": 1,
"node_type_id": "memoptimized-cluster-1"
}
Se o senhor precisar instalar a biblioteca no site worker, use o formato "cluster specification". Observe que os arquivos Python wheel devem ser carregados em DBFS e especificados como dependências pypi. Por exemplo:
{
"new_cluster": {
"spark_version": "7.5.x-scala2.12",
"num_workers": 1,
"node_type_id": "memoptimized-cluster-1"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Importante
.egge as dependências.jarnão são compatíveis com projetos MLflow.A execução de projetos MLflow com ambientes Docker não é suportada.
Você deve usar uma nova especificação clusters ao executar um projeto MLflow no Databricks. A execução de projetos em clusters existentes não é suportada.
Usando o SparkR
Para usar o SparkR em uma execução de projeto MLflow, o código do seu projeto deve primeiro instalar e importar o SparkR da seguinte maneira:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Seu projeto pode então inicializar uma sessão do SparkR e usar o SparkR normalmente:
sparkR.session()
...
Exemplo
Este exemplo mostra como criar um experimento, executar o projeto do tutorial MLflow em clusters Databricks, view a saída de execução Job e view a execução no experimento.
Requisitos
Instale o MLflow usando
pip install mlflow.Instalar e configurar a CLI da Databricks. O mecanismo de autenticação Databricks CLI é necessário para executar o Job em um Databricks cluster.
passo 1: criar uma experiência
No workspace, selecione Criar > Experimento do MLflow.
No campo Nome, insira
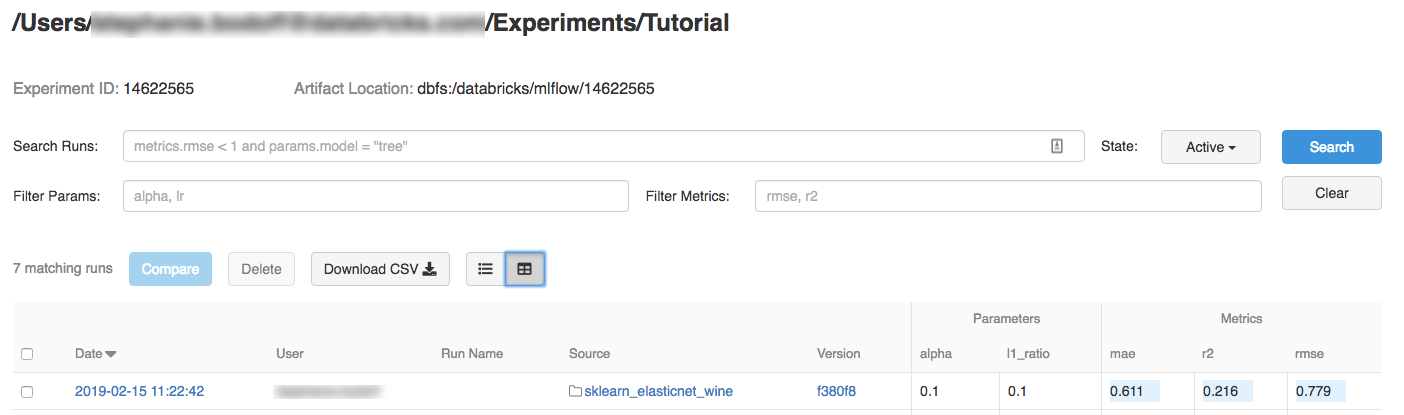
Tutorial.Clique em Criar. Anote o ID do experimento. Neste exemplo, é
14622565.
passo 2: execução do projeto tutorial do MLflow
As passos a seguir configuram a variável de ambiente MLFLOW_TRACKING_URI e executam o projeto, registrando os parâmetros de treinamento, as métricas e o modelo treinado para o experimento observado na passo anterior:
Defina a variável de ambiente
MLFLOW_TRACKING_URIpara o workspace Databricks.export MLFLOW_TRACKING_URI=databricks
execução do projeto tutorial MLflow, treinamento a wine model. Substitua
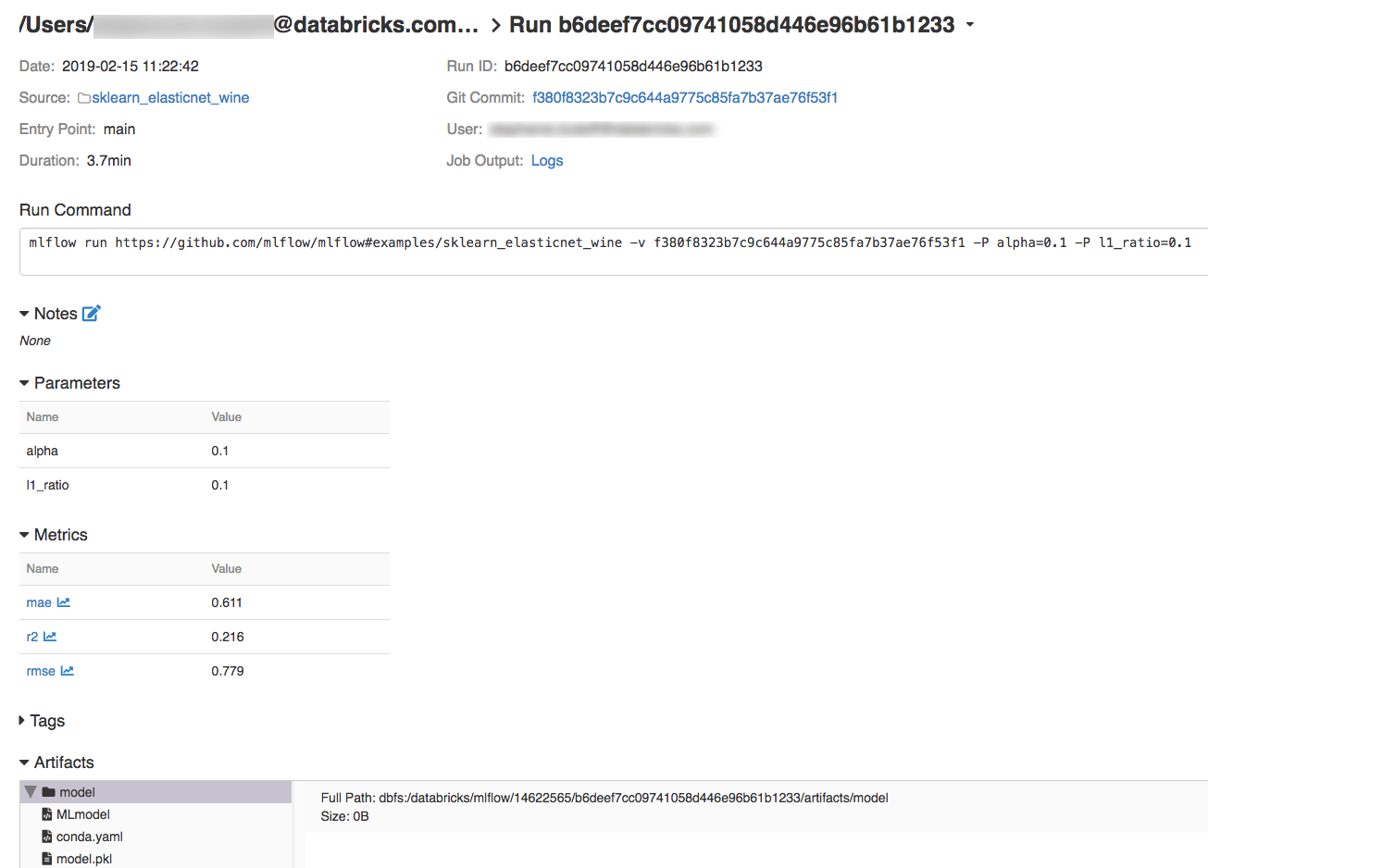
<experiment-id>pela ID da experiência que você anotou na passo anterior.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>
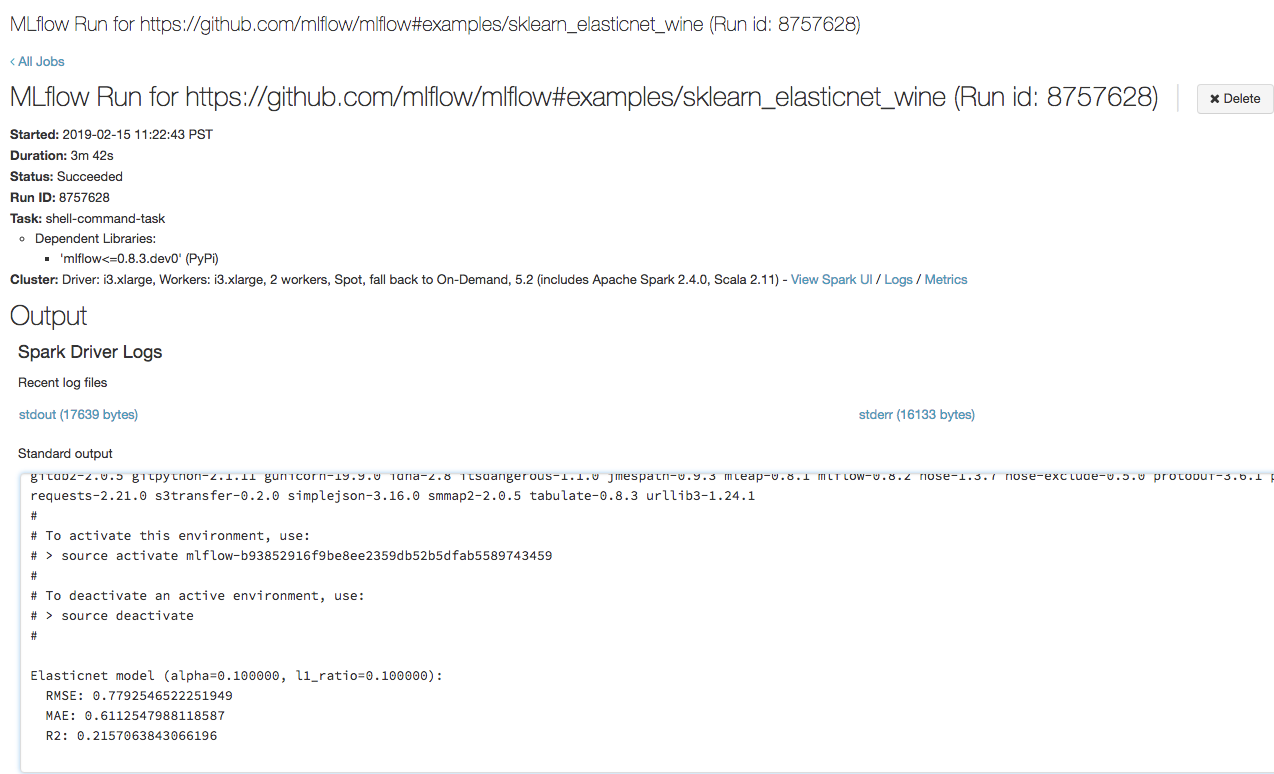
=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===
Copie o URL
https://<databricks-instance>#job/<job-id>/run/1na última linha da saída de execução do MLflow.
recurso
Para alguns exemplos de projetos MLflow, consulte a biblioteca de aplicativos MLflow, que contém um repositório de projetos prontos para execução destinados a facilitar a inclusão da funcionalidade ML em seu código.