Cache de consultas
O armazenamento em cache é uma técnica essencial para melhorar o desempenho dos sistemas de data warehouse, evitando a necessidade de recomputar ou buscar os mesmos dados várias vezes. No Databricks SQL, o armazenamento em cache pode acelerar significativamente a execução de consultas e minimizar o uso do warehouse, resultando em custos mais baixos e utilização mais eficiente dos recursos. Cada camada de cache melhora o desempenho da consulta, minimiza o uso de clusters e otimiza a utilização de recursos para uma experiência perfeita de data warehouse.
O armazenamento em cache oferece inúmeras vantagens no data warehouse, incluindo:
Velocidade: ao armazenar os resultados da consulta ou os dados acessados com frequência na memória ou em outros meios de armazenamento rápido, o armazenamento em cache pode reduzir drasticamente os tempos de execução da consulta. Esse armazenamento é particularmente vantajoso para consultas repetitivas, pois o sistema pode recuperar rapidamente os resultados armazenados em cache em vez de recalculá-los.
Redução do uso de clusters: O armazenamento em cache minimiza a necessidade de compute recurso adicional ao reutilizar resultados de computação anteriores. Isso reduz o tempo de atividade geral do armazém e a demanda por clusters compute adicionais, o que resulta em economia de custos e melhor alocação de recursos.
Tipos de caches de consulta no Databricks SQL
O Databricks SQL executa vários tipos de cache de consulta.
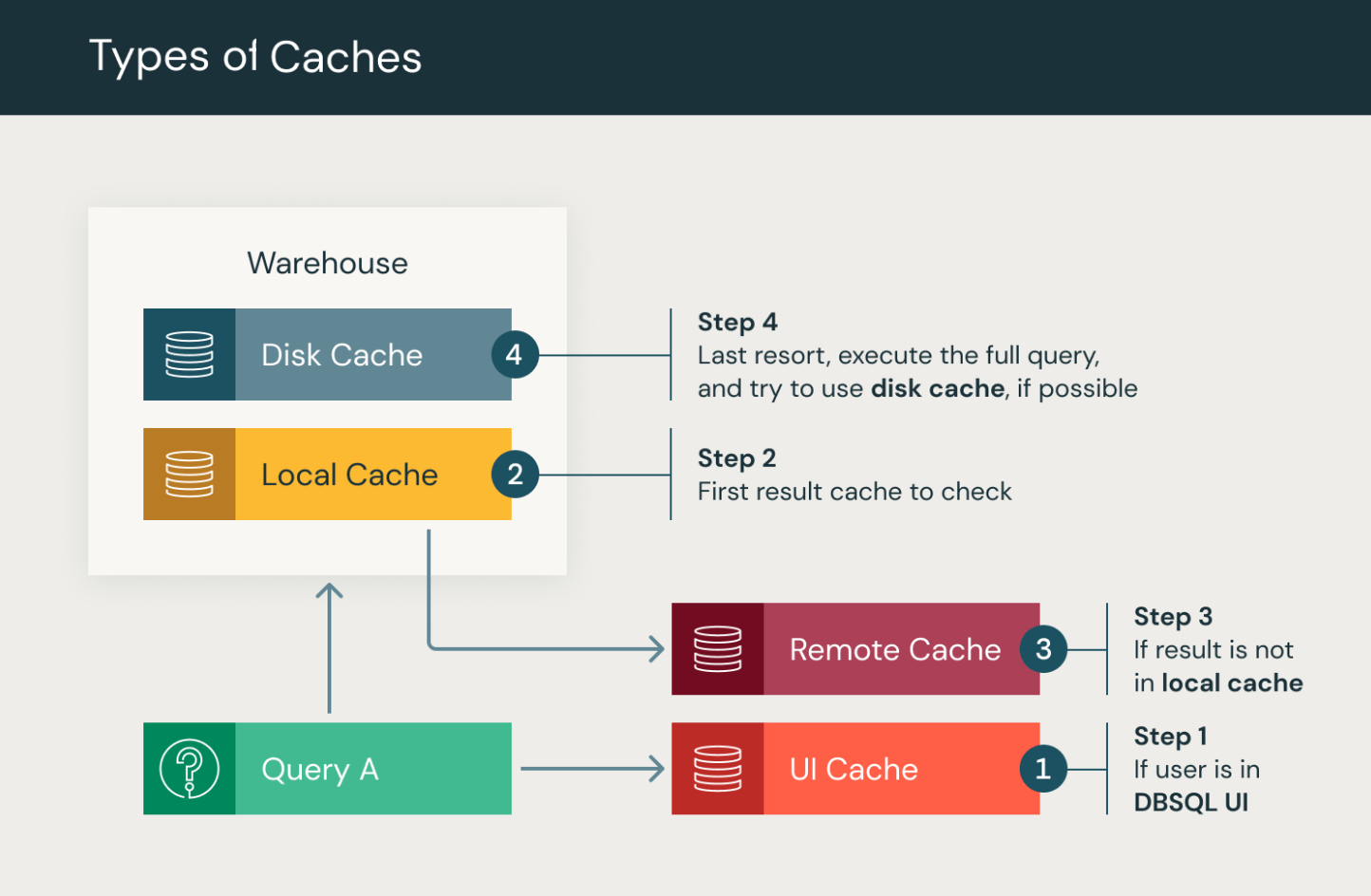
Cache daDatabricks SQL interface do usuário: Armazenamento em cache por usuário de todos os resultados de consultas e painéis na Databricks SQL interface do usuário . Quando os usuários abrem um dashboard ou uma consulta SQL pela primeira vez, o cache da interface do usuário do Databricks SQL exibe o resultado da consulta mais recente, incluindo os resultados de execuções agendadas.
O cache do Databricks SQL UI tem um ciclo de vida de no máximo 7 dias. O cache está localizado no sistema de arquivos do Databricks em account. O senhor pode excluir os resultados da consulta executando novamente a consulta que não deseja mais armazenar. Após a reexecução, os resultados da consulta antiga são removidos do cache. Além disso, o cache é invalidado quando as tabelas subjacentes são atualizadas.
Cache de resultados: Cache por clusters de resultados de consultas para todas as consultas por meio do SQL warehouse. O cache de resultados inclui caches de resultados locais e remotos, que trabalham juntos para melhorar o desempenho da consulta, armazenando os resultados da consulta na memória ou em mídias de armazenamento remoto.
Cache local: O cache local é um cache na memória que armazena os resultados da consulta durante o tempo de vida dos clusters ou até que o cache esteja cheio, o que ocorrer primeiro. Esse cache é útil para acelerar as consultas repetitivas, eliminando a necessidade de recomputar os mesmos resultados. No entanto, quando os clusters são interrompidos ou reiniciados, o cache é limpo e todos os resultados da consulta são removidos.
Cache de resultados remotos: O cache de resultados remotos é um sistema de cache somente serverlessque retém os resultados da consulta persistindo-os como dados do sistema workspace. Como resultado, esse cache não é invalidado pela interrupção ou reinicialização de um SQL warehouse. O cache de resultados remotos aborda um ponto problemático comum no armazenamento em cache dos resultados da consulta na memória, que só permanece disponível enquanto o recurso compute estiver em execução. O cache remoto é um cache compartilhado persistente em todos os depósitos em um Databricks workspace.
O acesso ao cache de resultados remotos requer um depósito em execução. Ao processar uma consulta, os clusters procuram primeiro em seu cache local e, em seguida, no cache de resultados remotos, se necessário. A consulta só será executada se o resultado da consulta não estiver armazenado em cache em nenhum dos cache. Tanto o cache local quanto o remoto têm um ciclo de vida de 24 horas, que começa na entrada do cache. O cache de resultados remotos persiste após a interrupção ou reinicialização de um SQL warehouse. Ambos os caches são invalidados quando as tabelas subjacentes são atualizadas.
O cache de resultados remotos está disponível para consultas usando clientes ODBC/JDBC e SQL Statement API.
Para desativar o armazenamento em cache do resultado da consulta, o senhor pode executar
SET use_cached_result = falseno editor SQL.Importante
O senhor deve usar essa opção somente em testes ou benchmarking.
Cache de disco: Cache local de SSD para dados lidos do armazenamento de dados para consultas por meio do SQL warehouse. O cache de disco foi projetado para melhorar o desempenho da consulta armazenando dados no disco, o que permite leituras de dados aceleradas. Os dados são automaticamente armazenados em cache quando os arquivos são obtidos, utilizando um formato intermediário rápido. Ao armazenar cópias dos arquivos no armazenamento local anexado aos nós do compute, o cache de disco garante que os dados estejam localizados mais perto do trabalhador, resultando em melhor desempenho da consulta. Consulte Otimizar o desempenho com cache em Databricks.
Além de sua função principal, o cache de disco detecta automaticamente as alterações nos arquivos de dados subjacentes. Quando detecta alterações, o cache é invalidado. O cache de disco compartilha as mesmas características de ciclo de vida que o cache de resultados local. Isso significa que, quando os clusters são interrompidos ou reiniciados, o cache é limpo e precisa ser preenchido novamente.
O cache de resultados de consultas e o cache de disco afetam as consultas na Databricks SQL interface do usuário e no BI e em outros clientes externos.