AutoML による分類
AutoML を使用して、特定の入力のラベルまたはカテゴリを予測するための最適な分類アルゴリズムとハイパーパラメーター構成を自動的に見つけます。
UI を使用した分類エクスペリメントの設定
次の手順で、 AutoML UI を使用して分類問題を設定できます。
サイドバーで、「 エクスペリメント」を選択します。
[分類] カードで、[トレーニングの開始] を選択します。
「エクスペリメントAutoML設定」ページが表示されます。このページでは、 AutoML プロセスを構成し、データセット、問題タイプ、予測するターゲット列またはラベル列、エクスペリメント 実行の評価とスコアリングに使用するメトリクス、および停止条件を指定します。
「コンピュート」フィールドで、実行中のクラスターを選択します Databricks Runtime ML。
[データセット] で、 [参照] を選択します。
使用するテーブルに移動し、[ 選択] をクリックします。 テーブル・スキーマが表示されます。
Databricks Runtime 10.3 ML 以降では、 AutoML がトレーニングに使用する列を指定できます。 予測ターゲットとして選択した列や、データを分割する時間列は削除できません。
Databricks Runtime 10.4 LTS ML 以降では、[ 代入] ドロップダウンから選択して 、null 値の代入方法を指定できます 。デフォルトによって、 AutoML は列のタイプと内容に基づいて代入方法を選択します。
注:
デフォルト以外の代入方法を指定した場合、 AutoML は セマンティック型検出を実行しません。
[予測ターゲット] フィールドをクリックします。ドロップダウンが表示され、スキーマに表示されている列が一覧表示されます。 モデルで予測する列を選択します。
エクスペリメント名フィールドには、デフォルト名が表示されます。変更するには、フィールドに新しい名前を入力します。
また、次のこともできます。
高度な構成
[ Advanced Configuration (optional)] セクションを開いて、これらのパラメーターにアクセスします。
評価メトリクスは、実行のスコアリングに使用される 主要なメトリクス です。
Databricks Runtime 10.4 LTS ML 以降では、トレーニング フレームワークを考慮対象から除外できます。 By Default は、AutoML トレーニングする models using frameworks listed under AutoML algorithms .
停止条件を編集できます。 デフォルトの停止条件は次のとおりです。
エクスペリメントの予測は、120分後に停止します。
Databricks Runtime 10.4 LTS ML以下では、エクスペリメントの分類と回帰については、60 分後または 200 回の試行を完了した後のいずれか早い方で停止します。Databricks Runtime 11.0 ML 以降では、試行回数は停止条件として使用されません。
Databricks Runtime 10.4 LTS ML 以降では、エクスペリメントの分類と回帰のために、AutoML に早期停止が組み込まれています。Validation メトリクスが改善されなくなった場合、トレーニングとチューニングモデルは停止します。
Databricks Runtime 10.4 LTS ML 以降では、トレーニング、検証、テストのデータを時系列で分割する
time columnを選択できます ( 分類 と 回帰にのみ適用されます)。Databricks では、 [データ ディレクトリ ] フィールドには設定しないことをお勧めします。 これにより、データセットを MLflow アーティファクトとして安全に保存するためのデフォルトの動作がトリガーされます。 DBFSパスを指定できますが、この場合、データセットはAutoMLエクスペリメントのアクセス権を継承しません。
エクスペリメントを実行し結果を確認する
AutoMLエクスペリメントを開始するには、[AutoMLを開始] をクリックします。エクスペリメントが実行を開始し、 AutoML トレーニング ページが表示されます。 実行テーブルを更新するには、[  ] をクリックします。
] をクリックします。
エクスペリメントの進行状況を表示
このページでは、次のことができます。
エクスペリメントはいつでも停止できます。
データ探索ノートブックを開きます。
モニターの実行。
任意の実行の実行ページに移動します。
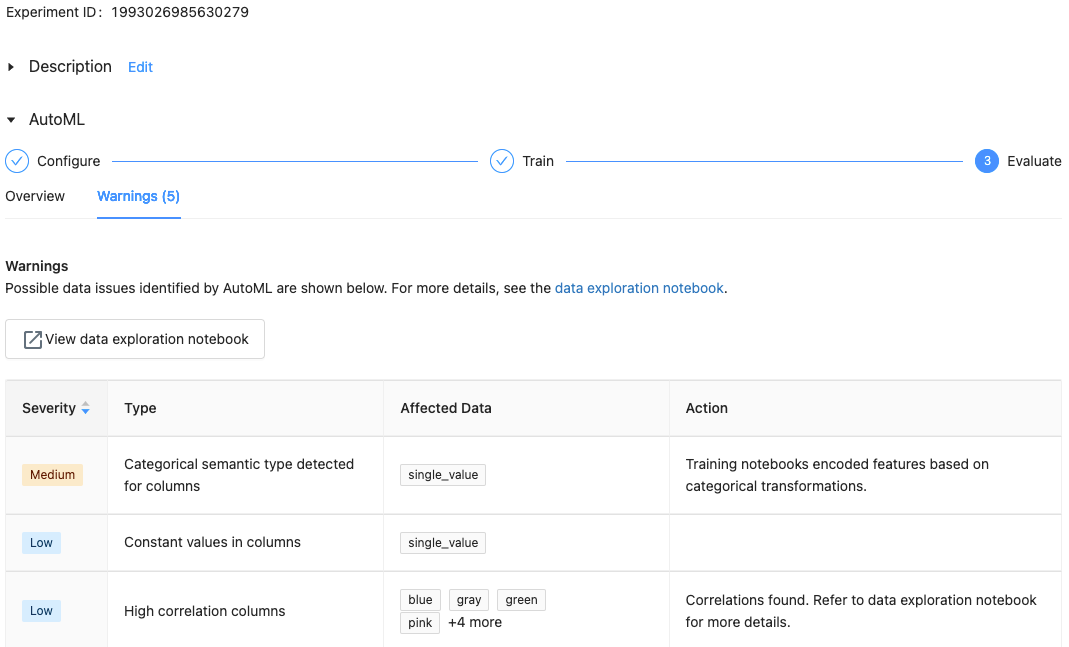
Databricks Runtime 10.1 ML 以降では、AutoML は、サポートされていない列の種類や高カーディナリティ列など、データセットの潜在的な問題に対する警告を表示します。
注:
Databricks は、潜在的なエラーや問題を示すために最善を尽くします。 ただし、これは包括的ではなく、探している問題やエラーを捉えていない可能性があります。
データセットの警告を表示するには、エクスペリメントの完了後に、トレーニングページまたはエクスペリメントページの 警告 タブをクリックします。
結果の表示
エクスペリメントが完了すると、次の操作を実行できます。
登録する MLflow.
[ 最適なモデルのノートブックを表示 ] を選択して、最適なモデルを作成したノートブックを確認および編集します。
[ データ探索ノートブックの表示 ] を選択して、データ探索ノートブックを開きます。
実行テーブルで実行を検索、フィルタリング、およびソートします。
任意の実行の詳細を表示します。
試用版の実行のソース コードを含む生成されたノートブックは、MLflow の実行をクリックすると見つかります。 ノートブックは、実行ページの [アーティファクト ] セクションに保存されます。 このノートブックをダウンロードしてワークスペースにインポートできます (ワークスペースの管理者によってアーティファクトのダウンロードが有効になっている場合)。
実行結果を表示するには、[ モデル ] 列または [開始時間 ] 列をクリックします。 実行ページが表示され、試用実行に関する情報 (パラメーター、メトリクス、タグなど) と、実行によって作成されたアーティファクト (モデルなど) が表示されます。 このページには、モデルで予測を行うために使用できるコード スニペットも含まれています。
後でこのエクスペリメント AutoML に戻るには、 エクスペリメントページの表で見つけることができます。 各 AutoML エクスペリメントの結果 (データ探索やトレーニング ノートブックなど) は、エクスペリメントを実行したユーザーの ホーム フォルダー 内の databricks_automl フォルダーに格納されます。
モデルを登録しデプロイする
モデルを登録してデプロイするには、 AutoML UI を使用します。
登録するモデルの [モデル ] 列のリンクを選択します。 実行が完了すると、一番上の行が最適なモデルになります (プライマリ メトリクスに基づく)。
 を選択して、Model Registryでモデルを登録します。
を選択して、Model Registryでモデルを登録します。サイドバーで「
 モデル」を選択して、Model Registryに移動します。
モデル」を選択して、Model Registryに移動します。モデル テーブルでモデルの名前を選択します。
No module named ‘pandas.core.indexes.numeric
AutoML を使用して構築されたモデルをモデルサービングで提供すると、 No module named 'pandas.core.indexes.numericエラーが表示されることがあります。
これは、 AutoML とモデルサービング エンドポイント環境の間でpandas バージョンが互換性がないためです。 このエラーは、 add-pandas-dependency.py スクリプトを実行することで解決できます。 このスクリプトは、記録済みモデルの requirements.txt と conda.yaml を編集して、適切な pandas 依存関係バージョンを含めます。 pandas==1.5.3
モデルがログに記録された MLflow 実行の
run_idを含めるようにスクリプトを変更します。モデルを MLflow モデルレジストリに再登録する
新しいバージョンの MLflow モデルを提供してみてください。