カスタムモデルサービングエンドポイントを作成する
プレビュー
Mosaic AI Model Serving は パブリック プレビュー 段階にあり、 us-east1 と us-central1でサポートされています。
この記事では、Databricks モデル サービング を使用して カスタム モデル を提供するモデルサービング エンドポイントを作成する方法について説明します。
モデルサービングでは、サービング エンドポイントの作成に関して次のオプションが提供されます。
サービング UI
REST API
MLflow デプロイメント SDK
生成AI モデルを提供するエンドポイントの作成については、「 エンドポイントを提供する基盤モデルの作成」を参照してください。
要件
ワークスペースはサポートされているリージョン内にある必要があります。
モデルでカスタムライブラリまたはプライベートミラーサーバーのライブラリを使用する場合は、モデルエンドポイントを作成する前に、「 Model Servingでカスタム Python ライブラリを使用する 」を参照してください。
MLflow Deployments SDK を使用してエンドポイントを作成するには、MLflow Deployment クライアントをインストールする必要があります。 インストールするには、次を実行します。
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
アクセス制御
エンドポイント管理のためのモデルサービング エンドポイントのアクセス制御オプションを理解するには、 「モデルサービング エンドポイントのアクセス許可を管理する」を参照してください。
また、モデルサービングの認証情報を保存するために環境変数を追加することもできます。 モデルサービングエンドポイントからリソースへのアクセスを設定するを参照してください。
エンドポイントを作成する
サービング UI を使用して、モデル・サービングのエンドポイントを作成できます。
サイドバーの [ 配信 ] をクリックして、配信 UI を表示します。
[ サービス エンドポイントの作成] をクリックします。
Unity Catalog に登録されているモデルの場合:
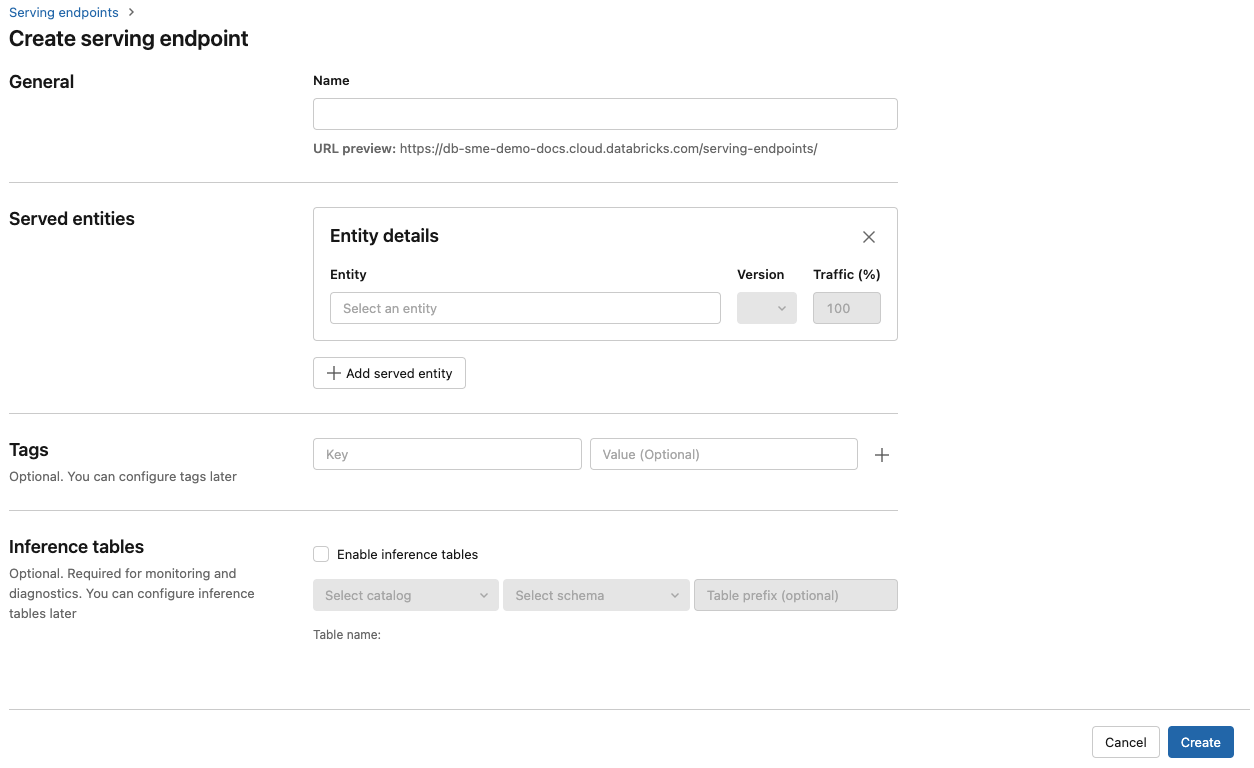
[ 名前 ] フィールドに、エンドポイントの名前を入力します。
[Served entities] セクションで、[Entity] フィールドをクリックして [Select served entity] フォームを開きます。
提供するモデルの種類を選択します。 フォームは、選択内容に基づいて動的に更新されます。
提供するモデルとモデル バージョンを選択します。
配信モデルにルーティングするトラフィックの割合を選択します。
使用するCPUまたはGPUコンピュートのサイズを選択します。 GPUはGPU_MEDIUMコンピュートのみ対応しています。
[コンピュート スケールアウト] で、このサーブ モデルが同時に処理できる要求の数に対応するコンピュート スケールアウトのサイズを選択します。この数値は、QPS x モデルの実行時間とほぼ等しくする必要があります。 使用可能なサイズは、0 から 4 の要求の場合は Small 、 要求は Medium 8 から 16、要求は Large です ( 16 から 64 の要求の場合)。
使用していないときにエンドポイントをゼロにスケーリングするかどうかを指定します。
「作成」をクリックします。[Serving endpoints ] ページが表示され、[ Serving endpoint state ] が [Not Ready] と表示されます。
REST API を使用してエンドポイントを作成できます。 POST /api/2.0/serving-endpoints を参照してください。 エンドポイント構成パラメーターの場合。
次の例では、 Unity Catalog モデルレジストリに登録されている ads1 モデルの最初のバージョンを提供するエンドポイントを作成します。 Unity Catalogからモデルを指定するには、親カタログとスキーマを含む完全なモデル名 (catalog.schema.example-model など) を指定します。
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
},
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "4",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
},
{
"served_model_name": "my-ads-model-4",
"traffic_percentage": 20
}
]
}
},
"tags": [
{
"key": "team",
"value": "data science"
}
]
}
次に、応答の例を示します。 エンドポイントの config_update 状態は NOT_UPDATING で、提供されたモデルは READY 状態です。
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model-3",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "catalog.schema.my-ads-model-3",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
MLflow デプロイ には、作成、更新、削除タスク用の API が用意されています。 これらのタスクの APIs は、エンドポイントを提供するための REST API と同じパラメーターを受け入れます。 POST /api/2.0/serving-endpoints を参照してください。 エンドポイント構成パラメーターの場合。
次の例では、 Unity Catalog モデルレジストリに登録されている my-ads-model モデルの 3 番目のバージョンを提供するエンドポイントを作成します。 親カタログとスキーマを含む完全なモデル名を指定する必要があります (例: catalog.schema.example-model)。
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
}
}
)
また、次のこともできます。
GPU ワークロードの種類
GPU デプロイは、次のパッケージ バージョンと互換性があります。
PyTorch 1.13.0 - 2.0.1
TensorFlow 2.5.0 - 2.13.0
MLflow 2.4.0 以降
GPU を使用してモデルをデプロイするには、エンドポイントの作成時、または API を使用したエンドポイント構成の更新として、エンドポイント構成にworkload_typeフィールドを含めます。 Serving UI を使用して GPU ワークロード用にエンドポイントを構成するには、 [コンピュート タイプ]ドロップダウンから目的の GPU タイプを選択します。
{
"served_entities": [{
"entity_name": "catalog.schema.ads1",
"entity_version": "2",
"workload_type": "GPU_MEDIUM",
"workload_size": "Small",
"scale_to_zero_enabled": false,
}]
}
次の表は、サポートされている使用可能な GPU ワークロードの種類をまとめたものです。
GPU ワークロードの種類 |
GPU インスタンス |
GPU メモリ |
|---|---|---|
|
L4 |
カスタムモデルのエンドポイントを変更する
カスタム モデル エンドポイントを有効にした後、必要に応じてコンピュート構成を更新できます。 この構成は、モデルに追加のリソースが必要な場合に特に役立ちます。 ワークロードのサイズとコンピュート構成は、モデルを提供するためにどのリソースが割り当てられるかにおいて重要な役割を果たします。
新しい設定の準備が整うまで、古い設定は予測トラフィックを提供し続けます。 更新が進行中の間は、別の更新を行うことはできません。 ただし、進行中の更新は、サービング UI からキャンセルできます。
モデル エンドポイントを有効にしたら、 [ エンドポイントの編集 ] を選択して、エンドポイントのコンピュート構成を変更します。
次の操作を実行できます。
いくつかのワークロードサイズから選択すると、オートスケールはワークロードサイズ内で自動的に構成されます。
使用していないときにエンドポイントをゼロにスケールダウンするかどうかを指定します。
配信モデルにルーティングするトラフィックの割合を変更します。
進行中の設定の更新をキャンセルするには、エンドポイントの詳細ページの右上にある [更新のキャンセル ] を選択します。 この機能は、サービング UI でのみ使用できます。
次に、REST API を使用したエンドポイント設定の更新例を示します。 PUT /api/2.0/serving-endpoints/{name}/config を参照してください。
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
MLflow Deployments SDK では、REST API と同じパラメーターが使用されます (「PUT /api/2.0/serving-endpoints/{name}/config」を参照)。 要求と応答のスキーマの詳細については、を参照してください。
次のコード サンプルでは、 Unity Catalogレジストモデルからのモデルを使用します。
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
モデルエンドポイントのスコアリング
モデルにスコアを付けるには、リクエストをモデルサービング エンドポイントに送信します。
「 カスタムモデルのサービングエンドポイントをクエリする」を参照してください。
「クエリ基盤モデル」を参照してください。
関連リソース
Python を使用したい場合は、 Databricks リアルタイム サービング Python SDKを使用できます。
ノートブックの例
次のノートブックには、モデルサービングエンドポイントを使用して起動して実行するために使用できる、さまざまな登録済みモデル Databricks が含まれています。 その他の例については、「 チュートリアル: カスタム モデルのデプロイとクエリ」を参照してください。
モデルの例は、「 ノートブックのインポート」の指示に従ってワークスペースにインポートできます。 いずれかの例からモデルを選択して作成したら、 Unity Catalogで登録する モデルサービングの UI ワークフロー ステップに従います。