sparklyr
注:
この機能は、このリリースの時点では Databricks on Google Cloud では使用できません。
Databricks は、ノートブック、ジョブ、RStudio デスクトップで sparklyr をサポートしています。 この記事では、sparklyr の使用方法について説明し、実行できるスクリプトの例を示します。 詳細については、「 Apache Spark への R インターフェイス 」を参照してください。
要件
Databricks は、 Databricks Runtime リリースごとに sparklyr の最新の安定バージョンを配布しています。 インストールされているバージョンの sparklyr をインポートすることで、Databricks R ノートブックまたは Databricks でホストされている RStudio Server 内で sparklyr を使用できます。
RStudio Desktop では、Databricks Connect を使用すると、ローカル コンピューターから Databricks クラスターに sparklyr を接続し、Apache Spark コードを実行できます。 「 Databricks Connect で sparklyr と RStudio Desktop を使用する」を参照してください。
sparklyrを Databricks クラスターに接続する
sparklyr 接続を確立するには、 spark_connect()の接続方法として "databricks" を使用できます。spark_connect() するための追加のパラメーターは必要なく、Spark は既に Databricks クラスターにインストールされているため、呼び出し spark_install() も必要ありません。
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
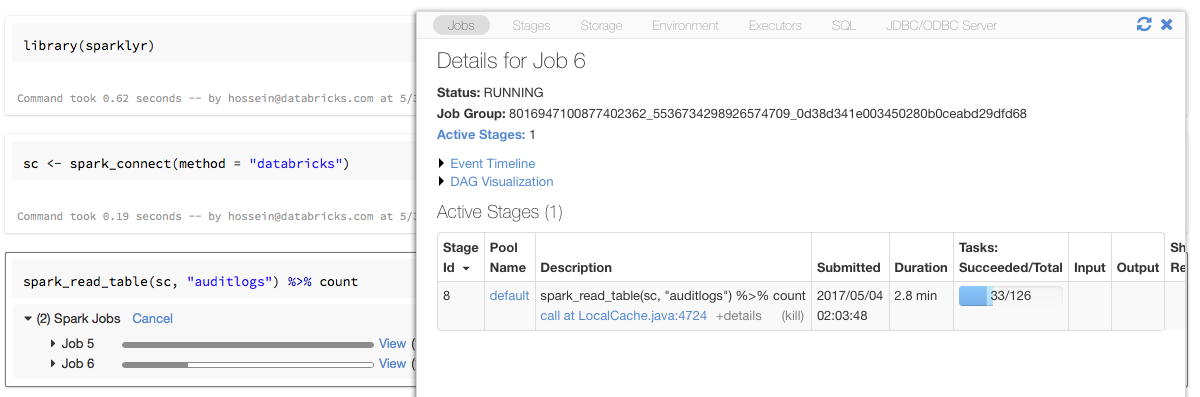
sparkly を使用したプログレスバーと Spark UI
上記の例のように sparklyr 接続オブジェクトを sc という名前の変数に割り当てると、Spark ジョブをトリガーする各コマンドの後にノートブックに Spark 進行状況バーが表示されます。 さらに、進行状況バーの横にあるリンクをクリックして、特定の Spark ジョブに関連付けられている Spark UI を表示できます。
sparklyr を使用する
sparklyr をインストールして接続を確立すると、他のすべての sparklyr API は通常どおりに動作します。 いくつかの例については、 ノートブックの例 を参照してください。
Sparklyrは通常、 dplyr などの他の Tidyverseパッケージ と一緒に使用されます。これらのパッケージのほとんどは、Databricks にプレインストールされているため便利です。それらをインポートしてAPIの使用を開始するだけです。
sparklyr と SparkR を一緒に使用する
SparkR と sparklyr は、1 つのノートブックまたはジョブで一緒に使用できます。 SparkRをsparklyrと一緒にインポートして、その機能を使用できます。 Databricks ノートブックでは、SparkR 接続は事前に構成されています。
SparkR の関数の一部は、dplyr のいくつかの関数をマスクします。
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
dplyr をインポートした後に SparkR をインポートする場合は、 dplyr::arrange()などの完全修飾名を使用して dplyr の関数を参照できます。 同様に、SparkR の後に dplyr をインポートすると、SparkR の関数は dplyr によってマスクされます。
または、不要な 2 つのパッケージのいずれかを選択的にデタッチすることもできます。
detach("package:dplyr")
「SparkR と sparklyr の比較」も参照してください。
spark-submit ジョブで sparklyr を使用する
Databricks で sparklyr を使用するスクリプトを、コードを少し変更して、spark-submit ジョブとして実行できます。 上記の手順の一部は、Databricks のspark-submit ジョブでの sparklyr の使用には適用されません。 特に、 spark_connectに Spark マスター URL を指定する必要があります。 例:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
サポートされていない機能
Databricks は、ローカル ブラウザを必要とするspark_web()やspark_log()などの Sparklyr メソッドをサポートしていません。 ただし、Spark UI は Databricks に組み込まれているため、Spark ジョブとログを簡単に検査できます。 「コンピュートドライバーとワーカーのログ」を参照してください。
ノートブックの例: Sparklyr デモ
その他の例については、「 R での DataFrames とテーブルの操作」を参照してください。