brilhante
Observação
Este recurso não está disponível no Databricks on Google Cloud a partir desta versão.
Databricks suporta sparklyr em Notebook, Job e RStudio Desktop. Este artigo descreve como você pode usar o sparklyr e fornece scripts de exemplo que você pode executar. Consulte Interface R para Apache Spark para obter mais informações.
Requisitos
O Databricks distribui a versão estável mais recente do sparklyr com cada versão do Databricks Runtime. Você pode usar o sparklyr no Databricks R Notebook ou dentro do RStudio Server hospedado no Databricks importando a versão instalada do sparklyr.
No RStudio Desktop, o Databricks Connect permite conectar o sparklyr da sua máquina local aos clusters do Databricks e executar o código Apache Spark. Consulte Usar sparklyr e RStudio Desktop com Databricks Connect.
Conectar sparklyr a clusters Databricks
Para estabelecer uma conexão sparklyr, você pode usar "databricks" como método de conexão em spark_connect(). Nenhum parâmetro adicional para spark_connect() é necessário, nem é necessário chamar spark_install() porque o Spark já está instalado em clusters Databricks.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
Barras de progresso e Spark UI com sparklyr
Se você atribuir o objeto de conexão sparklyr a uma variável chamada sc como no exemplo acima, verá as barras de progresso do Spark no Notebook após cada comando que aciona o Spark Job. Além disso, você pode clicar no link ao lado da barra de progresso para view a Spark UI associada ao Job do Spark fornecido.
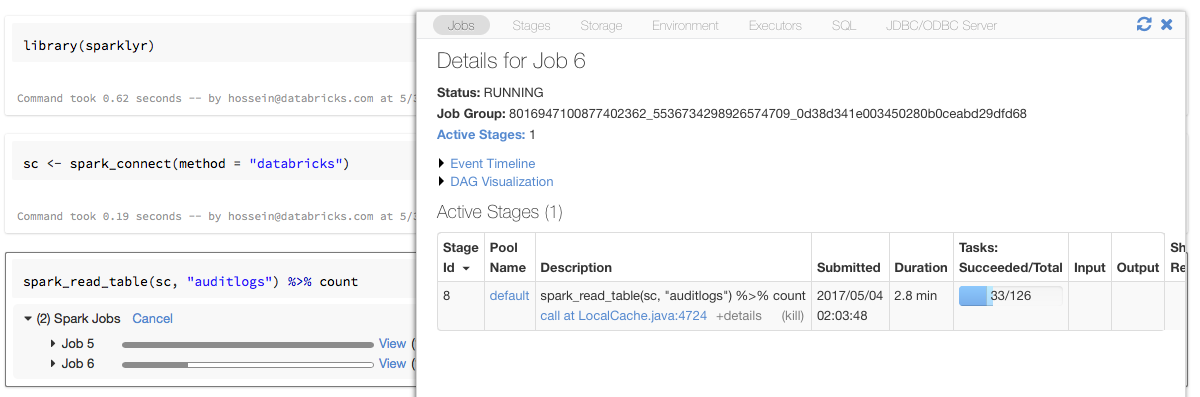
Use brilho
Depois de instalar o sparklyr e estabelecer a conexão, todas as outras APIs do sparklyr funcionam normalmente. Veja o Notebook de exemplo para alguns exemplos.
O sparklyr é geralmente usado junto com outros pacotes do , como o dplyr. A maioria desses pacotes é pré-instalada no Databricks para sua conveniência. Você pode simplesmente importá-los e começar a usar a API.
Use sparklyr e SparkR juntos
SparkR e sparklyr podem ser usados juntos em um único Notebook ou Job. Você pode importar o SparkR junto com o sparklyr e usar sua funcionalidade. No Databricks Notebook, a conexão SparkR é pré-configurada.
Algumas das funções no SparkR mascaram várias funções no dplyr:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
Se você importar SparkR depois de importar dplyr, poderá fazer referência às funções em dplyr usando os nomes totalmente qualificados, por exemplo, dplyr::arrange(). Da mesma forma, se você importar dplyr após SparkR, as funções em SparkR serão mascaradas por dplyr.
Como alternativa, você pode desanexar seletivamente um dos dois pacotes enquanto não precisar dele.
detach("package:dplyr")
Consulte também Comparando SparkR e sparklyr.
Use sparklyr no Jobde envio de faísca
Você pode executar scripts que usam sparklyr em Databricks como Spark-submit Job, com pequenas modificações de código. Algumas das instruções acima não se aplicam ao uso do sparklyr no Job de envio de faísca no Databricks. Em particular, você deve fornecer o URL mestre do Spark para spark_connect. Por exemplo:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Recurso não suportado
A Databricks não oferece suporte a métodos sparklyr, como spark_web() e spark_log(), que exigem um navegador local. No entanto, como o Spark UI é integrado ao Databricks, o senhor pode inspecionar facilmente o Spark Job e os logs. Consulte Registros do driver de computação e worker .
Notebook de exemplo: demonstração do Sparklyr
Para obter exemplos adicionais, consulte Trabalhar com DataFrames e tabelas em R.