tutorial: execução Python em um cluster e como um Job usando a extensão Databricks para Visual Studio Code
Este tutorial orienta o senhor na configuração da extensão Databricks para o Visual Studio Code e, em seguida, na execução do Python em um Databricks cluster e como um Databricks Job em seu workspace remoto. Consulte O que é a extensão Databricks para o Visual Studio Code?
Requisitos
Este tutorial requer isso:
O senhor instalou a extensão Databricks para o Visual Studio Code. Consulte Instalar a extensão Databricks para o Visual Studio Code.
O senhor tem um cluster Databricks remoto para usar. Anote o nome do cluster. Para view sua clusters disponível, na barra lateral Databricks workspace , clique em computar. Consulte Computação.
o passo 1: Criar um novo projeto Databricks
Neste passo, o senhor cria um novo projeto Databricks e configura a conexão com o site remoto Databricks workspace.
Inicie o Visual Studio Code, clique em Arquivo > Abrir pasta e abra uma pasta vazia em sua máquina de desenvolvimento local.
Na barra lateral, clique no ícone do logotipo da Databricks. Isso abre a extensão Databricks.
Em Configuration (Configuração ) view, clique em Create configuration (Criar configuração).
A paleta de comandos para configurar seu Databricks workspace é aberta. Para Databricks Host, digite ou selecione o URL da instância do seu espaço de trabalho, por exemplo,
https://1234567890123456.7.gcp.databricks.com.Selecione um perfil de autenticação para o projeto. Consulte Configurar autorização para a extensão Databricks para Visual Studio Code.
o passo 2: Adicione cluster informações à extensão Databricks e comece a cluster
Com o site Configuration view já aberto, clique em Select a cluster ou clique no ícone de engrenagem(Configure cluster).
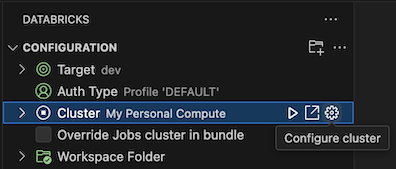
Na paleta de comandos, selecione o nome do site cluster que o senhor criou anteriormente.
Clique no ícone de reprodução(cluster começar) se ele ainda não estiver começando.
o passo 3: Criar e executar o código Python
Crie um arquivo de código Python local: na barra lateral, clique no ícone da pasta (Explorador).
No menu principal, clique em File > New File e escolha um arquivo Python. Nomeie o arquivo demo.py e salve-o na raiz do projeto.
Adicione o seguinte código ao arquivo e salve-o. Este código cria e exibe o conteúdo de um DataFrame PySpark básico:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()
# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+
Clique no ícone de execução em Databricks ao lado da lista da guia do editor e, em seguida, clique em upload e execução de arquivo. A saída aparece no Console de depuração view.
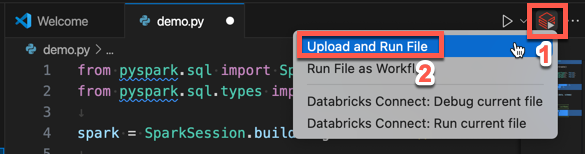
Como alternativa, no Explorer view, clique com o botão direito do mouse no arquivo
demo.pye, em seguida, clique em executar em Databricks > upload and execution File.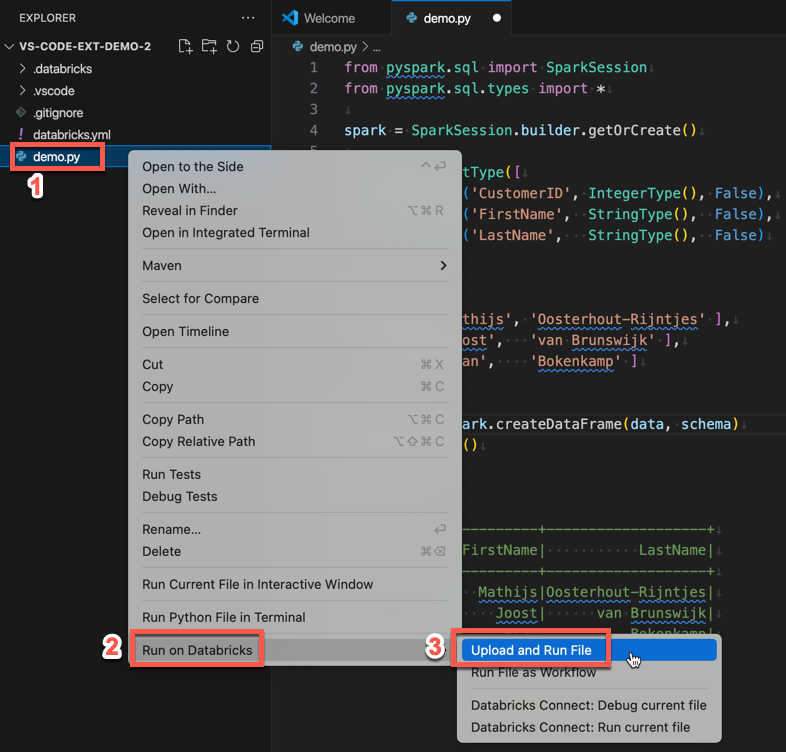
o passo 4: execução do código como um Job
Para executar demo.py como um trabalho, clique no ícone executar em Databricks ao lado da lista da guia do editor e, em seguida, clique em executar File como fluxo de trabalho. A saída aparece em um editor separado tab ao lado do editor de arquivos demo.py.
![]()
Como alternativa, clique com o botão direito do mouse no arquivo demo.py no painel Explorer e selecione executar em Databricks > executar arquivo como fluxo de trabalho.
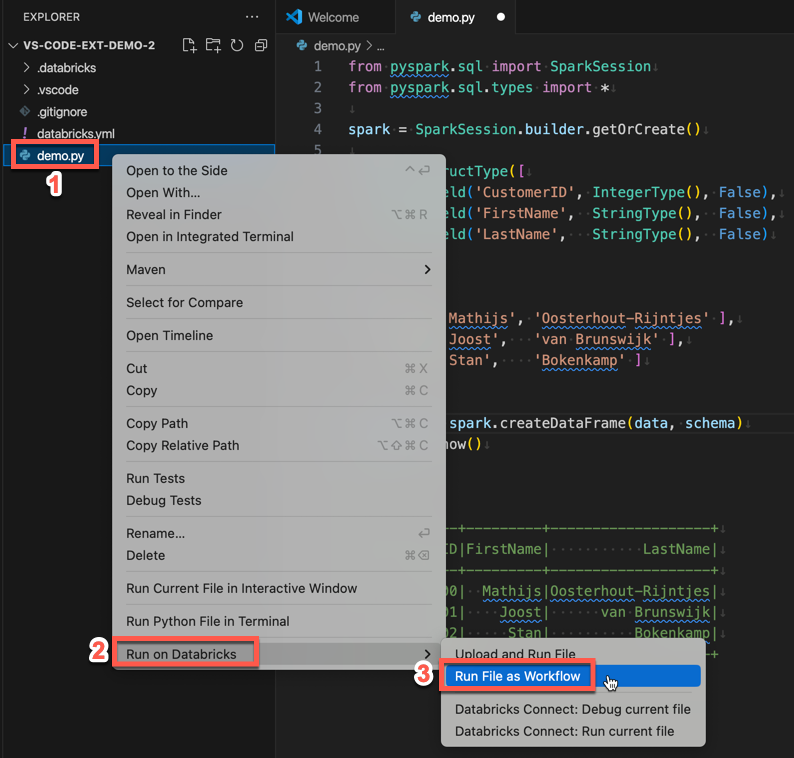
Próximas etapas
Agora que o senhor já usou com sucesso a extensão Databricks para o Visual Studio Code para upload um arquivo Python local e executá-lo remotamente, também é possível:
Explore Databricks ativo Bundles recurso e variáveis usando a UI da extensão. Consulte Databricks ativo Recurso de extensão de pacotes.
execução ou depuração do código Python com Databricks Connect. Consulte Depurar código usando o Databricks Connect para a extensão Databricks para Visual Studio Code.
executar um arquivo ou um Notebook como um Databricks Job. Consulte executar um arquivo em um cluster ou um arquivo ou Notebook como um Job em Databricks usando a extensão Databricks para o Visual Studio Code.
testes de execução com
pytest. Veja os testes de execução com o pytest usando a extensão Databricks para o Visual Studio Code.