チュートリアル: クラスターで Python を実行し、Visual Studio Code の Databricks 拡張機能を使用してジョブとして実行する
このチュートリアルでは、Visual Studio Code の Databricks 拡張機能を設定し、Databricks クラスターで Python を実行し、リモート ワークスペースで Databricks ジョブとして実行する方法について説明します。 「Visual Studio Code の Databricks 拡張機能とは」を参照してください。
要件
このチュートリアルでは、次のことが必要です。
Visual Studio Code 用の Databricks 拡張機能をインストールしました。 「Visual Studio Code の Databricks 拡張機能のインストール」を参照してください。
使用するリモート Databricks クラスターがあります。 クラスターの名前をメモします。 使用可能なクラスターを表示するには、 Databricks ワークスペースのサイドバーで [ コンピュート] をクリックします。 コンピュートを参照してください。
ステップ 1: 新しい Databricks プロジェクトを作成する
この手順では、新しい Databricks プロジェクトを作成し、リモート Databricks ワークスペースとの接続を構成します。
Visual Studio Code を起動し、[ファイル] > [フォルダーを開く ] をクリックして、ローカルの開発マシンで空のフォルダーを開きます。
サイドバーで、 Databricks のロゴアイコンをクリックします。 これにより、Databricks 拡張機能が開きます。
「Configuration」ビューで、「Create configuration」をクリックします。
Databricks ワークスペースを構成するための コマンド パレット が開きます。 [Databricks Host] で、ワークスペース インスタンスの URL (
https://1234567890123456.7.gcp.databricks.comなど) を入力または選択します。プロジェクトの認証プロファイルを選択します。 「Visual Studio Code の Databricks 拡張機能の承認を設定する」を参照してください。
ステップ 2: クラスター 情報を Databricks 拡張機能に追加し、クラスターを開始します
[Configuration] ビューが既に開いている状態で、[Select a cluster] をクリックするか、歯車 ([Configure cluster]) アイコンをクリックします。
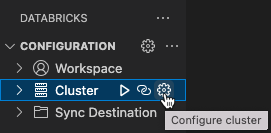
コマンド パレットで、前に作成したクラスターの名前を選択します。
再生アイコン(Start クラスター)がまだ開始されていない場合はクリックします。
ステップ 3: Python コードを作成して実行する
ローカルの Python コードファイルを作成する: サイドバーで、フォルダー (エクスプローラー) アイコンをクリックします。
メイン メニューで、[ ファイル] > [新しいファイル ] をクリックし、Python ファイルを選択します。 ファイルに demo.py という名前を付け、プロジェクトのルートに保存します。
次のコードをファイルに追加し、保存します。 このコードは、基本的なPySpark DataFrameの内容を作成して表示します。
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()
# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+
エディター タブの一覧の横にある [Databricks で実行 ] アイコンをクリックし、[ ファイルのアップロードと実行] をクリックします。 出力が [Debug Console ] ビューに表示されます。
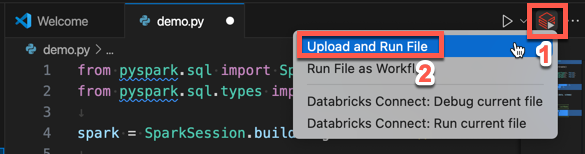
または、[ エクスプローラー ] ビューで
demo.pyファイルを右クリックし、[ Databricks で実行 ] > [ファイルのアップロードと実行] をクリックします。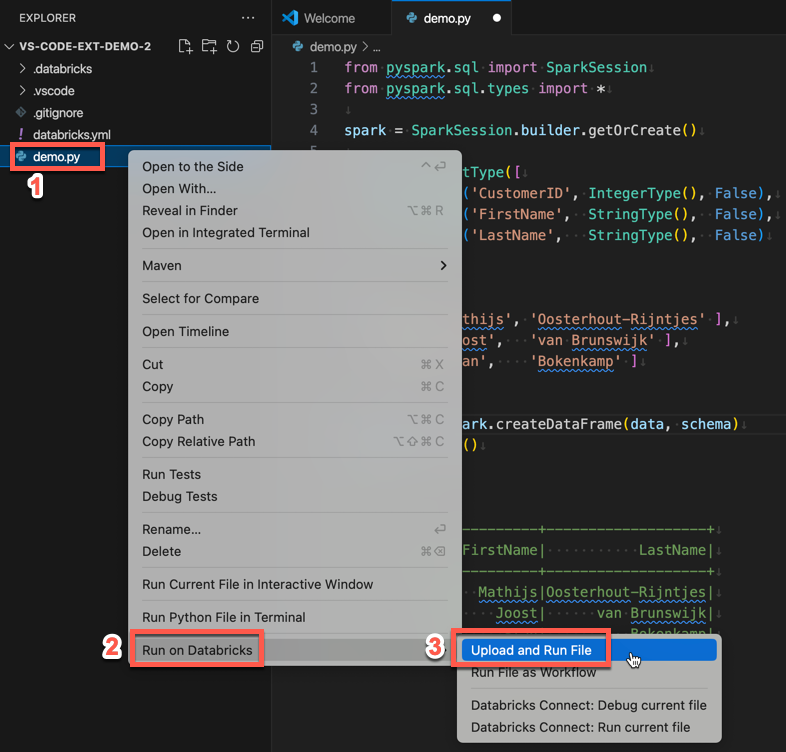
ステップ 4: コードをジョブとして実行する
demo.py をジョブとして実行するには、エディタ タブのリストの横にある [実行] アイコン Databricks をクリックし、[ワークフローとしてファイルを実行] をクリックします。出力は、 demo.py ファイルエディタの横にある別のエディタタブに表示されます。
![]()
または、[エクスプローラー] パネルで demo.py ファイルを右クリックし、[Databricks で実行] > [ファイルをワークフローとして実行] を選択します。
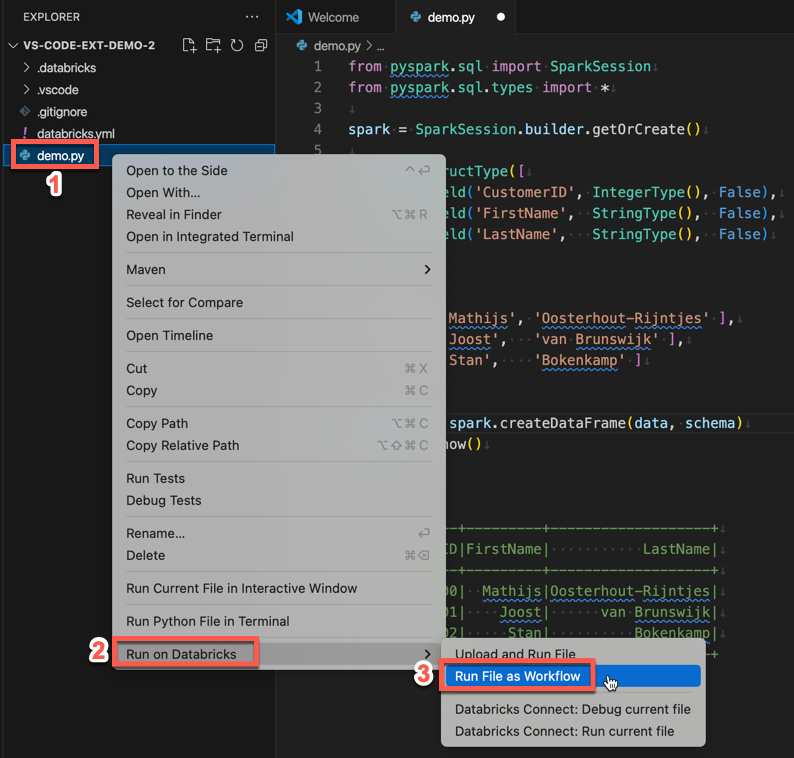
次のステップ
Visual Studio Code の Databricks 拡張機能を正常に使用してローカルの Python ファイルをアップロードし、リモートで実行したので、次の操作も実行できます。
拡張機能 UI を使用して、Databricks Asset Bundles のリソースと変数を探索します。 「Databricks Asset Bundles 拡張機能」を参照してください。
Databricks Connect を使用して Python コードを実行またはデバッグします。 Visual Studio Code の Databricks 拡張機能については、「Databricks Connect を使用したコードのデバッグ」を参照してください。
ファイルまたはノートブックを Databricks ジョブとして実行します。 「Visual Studio Code の Databricks 拡張機能を使用して、クラスター上のファイルを実行する、または Databricks のジョブとしてファイルまたはノートブックを実行する」を参照してください。
pytestでテストを実行します。「Visual Studio Code の Databricks 拡張機能を使用して pytest でテストを実行する」を参照してください。