Tutorial: implantar e consultar um modelo personalizado
Visualização
O Mosaic AI Model Serving está em Public Preview e é compatível com os sites us-east1 e us-central1.
Este artigo fornece os passos básicos para implantar e consultar um modelo personalizado, que é um modelo ML tradicional, usando Mosaic AI Model Serving. O modelo deve ser registrado no Unity Catalog.
Para saber como servir e implantar modelos generativos de AI, consulte os artigos a seguir:
o passo 1: registrar o modelo
Existem diferentes maneiras de logs seu modelo para modelo de atividade:
Técnica de registro |
Descrição |
|---|---|
Registro automático |
Isso é ativado automaticamente quando você usa o Databricks Runtime para machine learning. É a maneira mais fácil, mas oferece menos controle. |
Registro usando sabores integrados do MLflow |
Você pode logs manualmente o modelo com os tipos de modelo integrados do MLflow. |
Registro personalizado com |
Use isto se você tiver um modelo personalizado ou se precisar de passos extras antes ou depois da inferência. |
O exemplo a seguir mostra como logs seu modelo MLflow usando o tipo transformer e especificar os parâmetros necessários para seu modelo.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
Depois que o modelo for registrado, certifique-se de verificar se ele está registrado no Unity Catalog.
o passo 2: Criar endpoint usando a IU do Serving
Depois que seu modelo registrado for logs e você estiver pronto para servi-lo, você poderá criar um endpoint de modelo instalado usando a IU de serviço .
Clique em Envio na barra lateral para exibir a IU do Envio .
Clique em Criar endpoint de serviço.
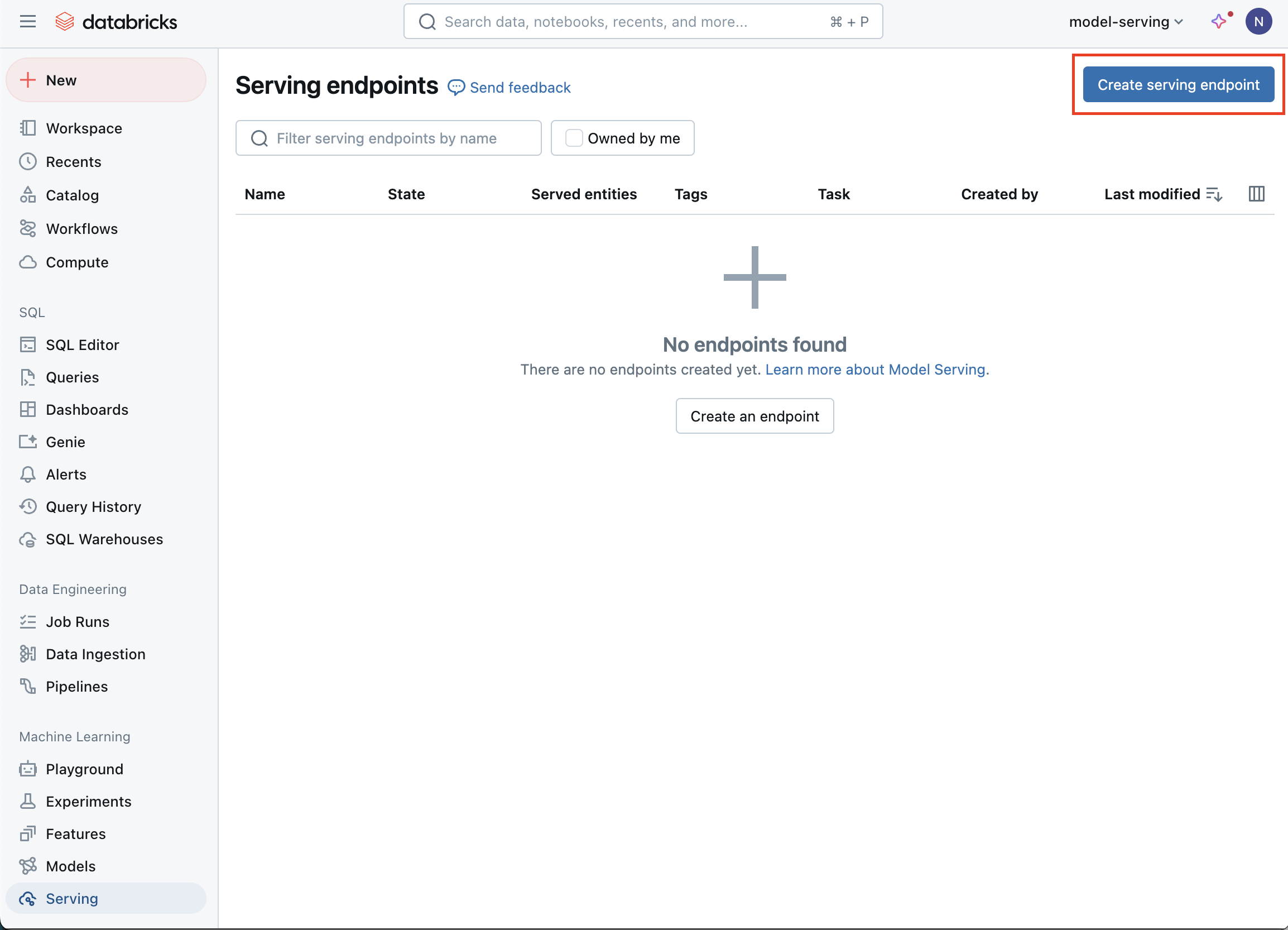
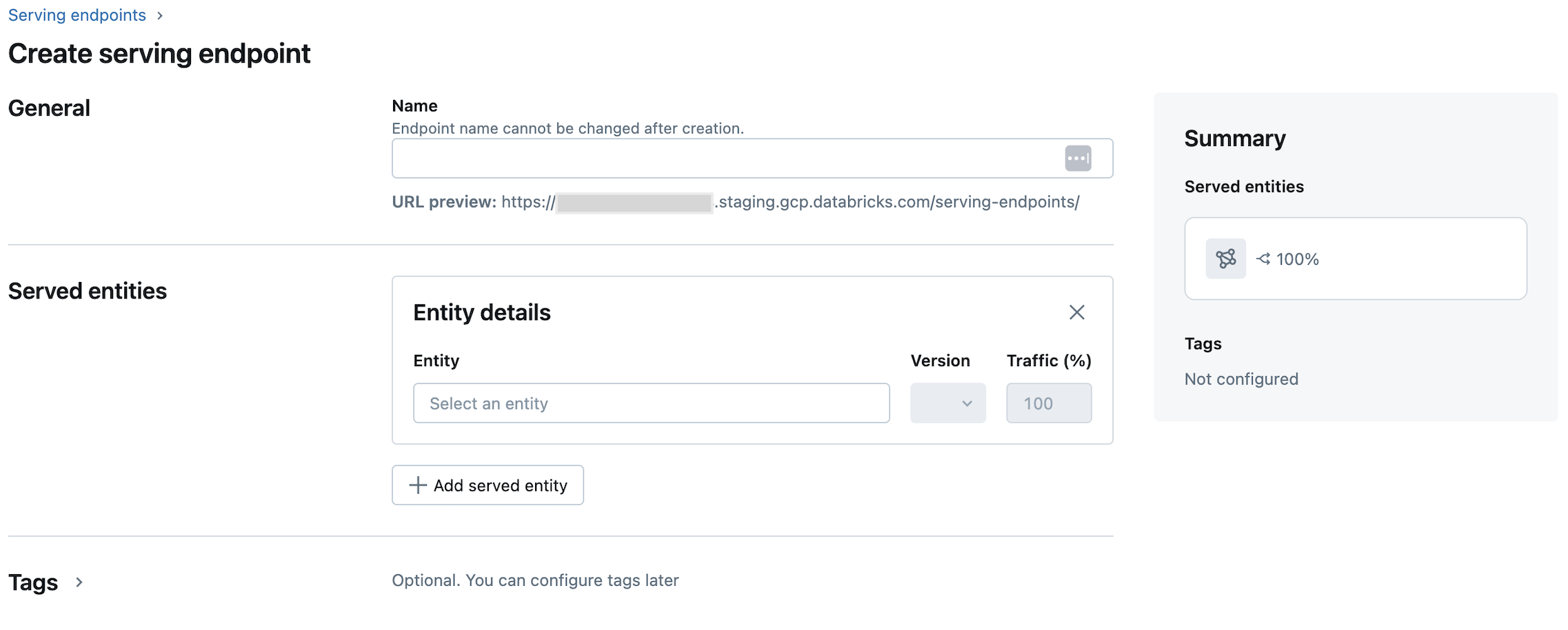
No campo Nome , forneça um nome para seu endpoint.
Na seção Entidades atendidas
Clique no campo Entidade para abrir o formulário Selecionar entidade atendida .
Selecione o tipo de modelo que você deseja servir. O formulário é atualizado dinamicamente com base na sua seleção.
Selecione qual modelo e versão do modelo você deseja veicular.
Selecione a porcentagem de tráfego a ser encaminhada para seu modelo atendido.
Selecione o tamanho do site compute a ser usado.
Em escalonamentocompute , selecione o tamanho do escalonamento compute que corresponde ao número de solicitações que esse modelo atendido pode processar ao mesmo tempo. Este número deve ser aproximadamente igual ao QPS x tempo de execução do modelo.
Os tamanhos disponíveis são Pequeno para 0 a 4 solicitações, Médio 8 a 16 solicitações e Grande para 16 a 64 solicitações.
Especifique se o endpoint deve escalar para zero quando não estiver em uso.
Clique em Criar. A página Servindo endpoints aparece com o estado do endpoint de veiculação mostrado como Não pronto.
Se o senhor preferir criar um endpoint programaticamente com a API de serviço da Databricks, consulte Criar endpoints de modelo de serviço personalizados.
o passo 3: Consulte o endpoint
A maneira mais fácil e rápida de testar e enviar solicitações de pontuação ao seu modelo atendido é usar a IU do Serving .
Na página de exibição endpoint query endpoint, selecione .
Insira os dados de entrada do modelo no formato JSON e clique em Enviar Solicitação. Se o modelo tiver sido logs com um exemplo de entrada, clique em Mostrar Exemplo para carregar o exemplo de entrada.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Para enviar solicitações de pontuação, construa um JSON com uma das chaves compatíveis e um objeto JSON correspondente ao formato de entrada. Consulte Ponto de extremidade de serviço de consulta para modelos personalizados para obter os formatos compatíveis e orientações sobre como enviar solicitações de pontuação usando a API.
Se o senhor planeja acessar o endpoint de veiculação fora da UI do Databricks Serving, precisará de um DATABRICKS_API_TOKEN.