TensorBoard
O TensorBoard é um conjunto de ferramentas de visualização para depuração, otimização e compreensão do TensorFlow, PyTorch, Hugging Face Transformers e outros programas machine learning .
Usar TensorBoard
Iniciar o TensorBoard no Databricks não é diferente de iniciá-lo em um Jupyter Notebook em seu computador local.
Carregue o comando mágico
%tensorboarde defina seu diretório logs .%load_ext tensorboard experiment_log_dir = <log-directory>
Invoque o comando mágico
%tensorboard.%tensorboard --logdir $experiment_log_dir
O servidor TensorBoard começa e exibe a interface do usuário inline no Notebook. Ele também fornece um link para abrir o TensorBoard em uma nova tab.
A captura de tela a seguir mostra a IU do TensorBoard começando em um diretório logs preenchido.
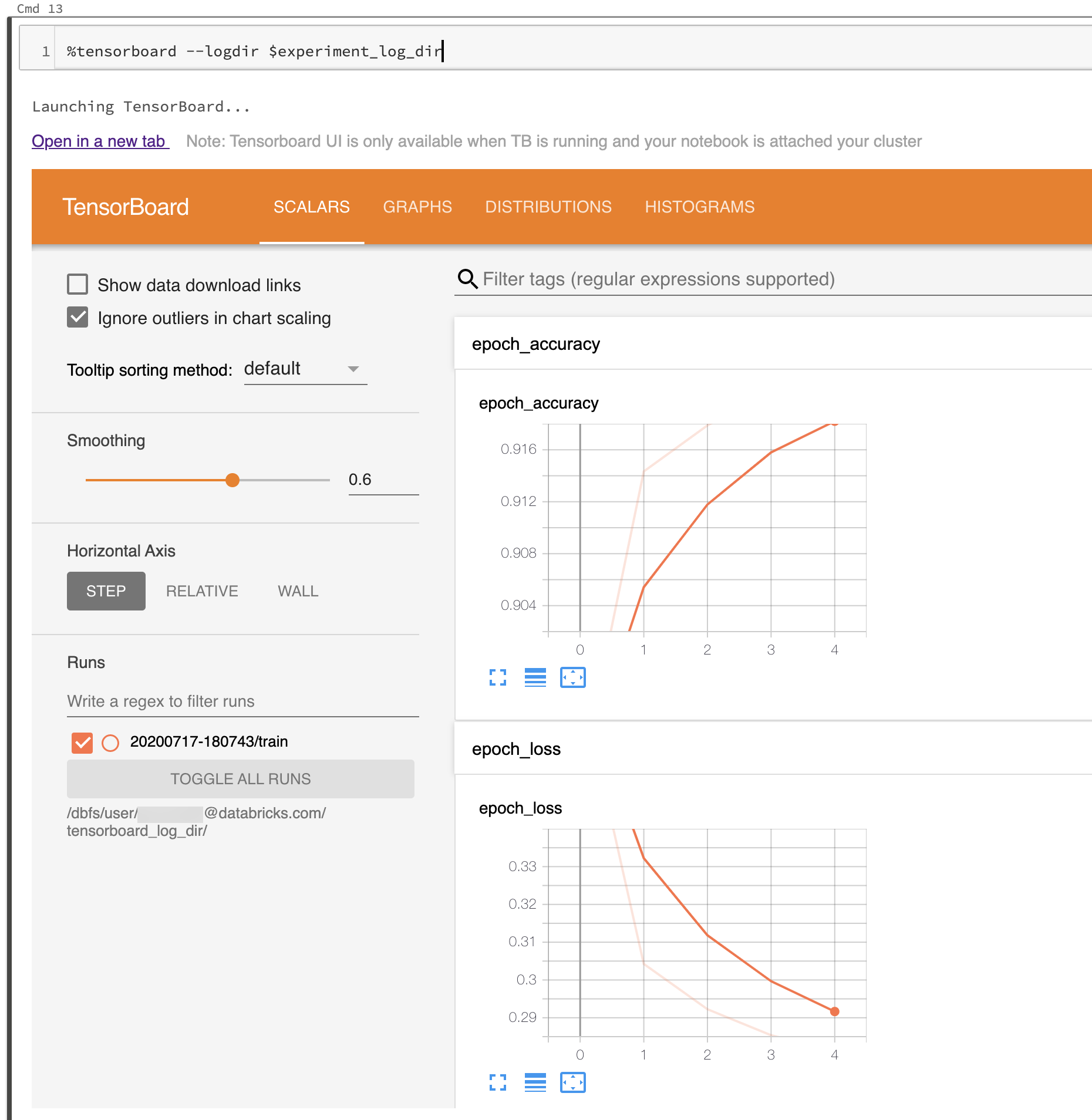
Você também pode começar o TensorBoard usando o módulo Notebook do TensorBoard diretamente.
from tensorboard import notebook
notebook.start("--logdir {}".format(experiment_log_dir))
Registros e diretórios do TensorBoard
O TensorBoard visualiza seus programas machine learning lendo logs gerados por callbacks e funções do TensorBoard no TensorBoard ou PyTorch. Para gerar logs para outra biblioteca do machine learning, você pode gravar logs diretamente usando os gravadores de arquivos do TensorFlow (consulte o Módulo: tf.summary para TensorFlow 2.xe consulte o Módulo: tf.compat.v1.summary para a API mais antiga no TensorFlow 1. x).
Para garantir que seus logs de experimento sejam armazenados de forma confiável, o Databricks recomenda gravar logs no armazenamento em cloud em vez de no sistema de arquivos clusters efêmeros. Para cada experimento, comece o TensorBoard em um diretório exclusivo. Para cada execução do seu código machine learning no experimento que gera logs, defina o retorno de chamada do TensorBoard ou o gravador de arquivo para gravar em um subdiretório do diretório do experimento. Dessa forma, os dados na IU do TensorBoard são separados em execução.
Leia a documentação oficial do TensorBoard para começar a usar o TensorBoard para logs informações para seu programa machine learning .
gerenciar processos do TensorBoard
Os processos do TensorBoard começam dentro do Databricks Notebook não são finalizados quando o Notebook é desconectado ou o REPL é recomeçar (por exemplo, quando você limpa o estado do Notebook). Para eliminar manualmente um processo do TensorBoard, envie a ele um sinal de encerramento usando %sh kill -15 pid. Processos do TensorBoard eliminados incorretamente podem corromper notebook.list().
Para listar os servidores TensorBoard atualmente em execução em seus clusters, com seus diretórios logs e IDs de processo correspondentes, execute notebook.list() no módulo TensorBoard Notebook .
Problemas conhecidos
A IU inline do TensorBoard está dentro de um iframe. Os recursos de segurança do navegador impedem que os links externos na interface do usuário funcionem, a menos que você abra o link em uma nova tab.
A opção
--window_titledo TensorBoard é substituída no Databricks.Por default, o TensorBoard verifica um intervalo de portas para selecionar uma porta para escutar. Se houver muitos processos do TensorBoard em execução nos clusters, todas as portas no intervalo de portas poderão ficar indisponíveis. Você pode contornar essa limitação especificando um número de porta com o argumento
--port. A porta especificada deve estar entre 6006 e 6106.Para que os links downloads funcionem, você deve abrir o TensorBoard em uma tab.
Ao usar o TensorBoard 1.15.0, a tab Projetor fica em branco. Como solução alternativa, para visitar a página do projetor diretamente, você pode substituir
#projectorno URL pordata/plugin/projector/projector_binary.html.O TensorBoard 2.4.0 tem um problema conhecido que pode afetar a renderização do TensorBoard se atualizado.
Se o senhor estiver registrando dados relacionados ao TensorBoard no DBFS ou UC Volumes, poderá receber um erro como
No dashboards are active for the current data set. Para evitar esse erro, é recomendável chamarwriter.flush()ewriter.close()depois de usarwriterpara log dados. Isso garante que todos os dados de registros sejam gravados corretamente e estejam disponíveis para renderização no site TensorBoard.