Sparkジョブ間のギャップ
そのため、ジョブのタイムラインには次のようなギャップが表示されます。
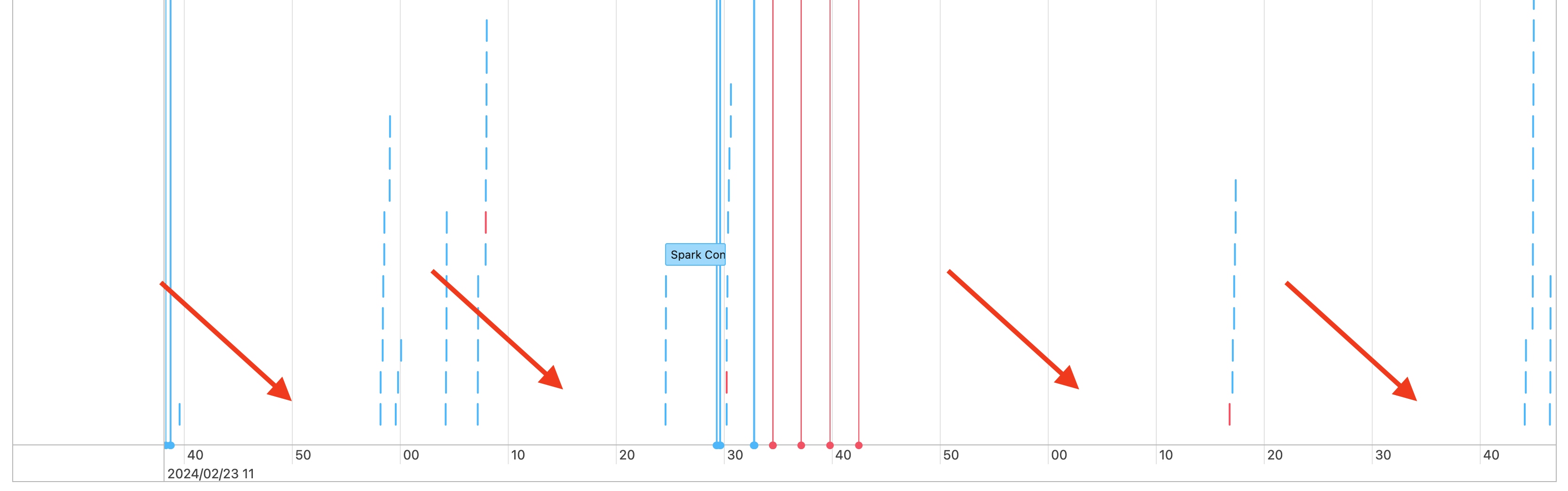
これが発生する理由はいくつかあります。 ギャップがワークロードに費やされる時間の大部分を占める場合は、これらのギャップの原因と、それが予期されるものかどうかを把握する必要があります。 ギャップの間に発生する可能性のあることがいくつかあります。
やるべき仕事はありません
ドライバーは複雑な実行プランをコンパイルしています
Spark以外のコードの実行
ドライバーが過負荷になっています
クラスターが故障しています
作業がない
万能コンピュートの場合、ギャップが生じる理由として最も可能性が高いのは、行うべき作業がないことです。 クラスターが実行中で、ユーザーがクエリを送信しているため、ギャップが発生することが予想されます。 これらのギャップは、クエリ送信間の時間です。
複雑な実行計画
たとえば、ループで withColumn() を使用すると、処理に非常にコストのかかるプランが作成されます。 ギャップは、ドライバーが単に計画の作成と処理に費やしている時間である可能性があります。 その場合は、コードを簡略化してみてください。 selectExpr()を使用して、複数のwithColumn()呼び出しを 1 つの式に結合するか、コードを SQL に変換します。 Python を使用して文字列関数でクエリを操作し、SQL を Python コードに埋め込むこともできます。 これにより、多くの場合、この種の問題が解決されます。
非Sparkコードの実行
Spark コードは、SQL で記述されるか、 PySparkなどの Spark API を使用して記述されます。 Spark 以外のコードの実行は、タイムラインにギャップとして表示されます。 たとえば、Python でネイティブ Python 関数を呼び出すループを作成できます。 このコードは Spark では実行されず、タイムラインにギャップとして表示される場合があります。 コードが Spark を実行しているかどうかわからない場合は、ノートブックで対話的に実行してみてください。 コードが Spark を使用している場合は、セルの下に Spark ジョブが表示されます。

また、セルの下のSpark ジョブドロップダウンを展開して、ジョブがアクティブに実行されているかどうかを確認することもできます (Spark が現在アイドル状態の場合)。 Spark を使用していない場合は、セルの下にSpark ジョブが表示されないか、アクティブなジョブがないことがわかります。 コードを対話的に実行できない場合は、コードにログインして、タイムスタンプによってコードのセクションのギャップを一致させることができるかどうかを確認できますが、これは難しい場合があります。
タイムラインに Spark 以外のコードの実行によるギャップがある場合は、そのギャップ中にワーカーがすべてアイドル状態になり、コストが無駄になっている可能性があります。 これは意図的で避けられないことかもしれませんが、Spark を使用するためにこのコードを記述できれば、クラスターを最大限に活用できます。 Spark の使い方を学ぶには、まずこのチュートリアルから始めましょう。
ドライバーが過負荷になっています
ドライバーが過負荷になっているかどうかを判断するには、クラスターメトリックを確認する必要があります。
クラスターが DBR 13.0 以降の場合は、このスクリーンショットで強調表示されている[メトリック]をクリックします。
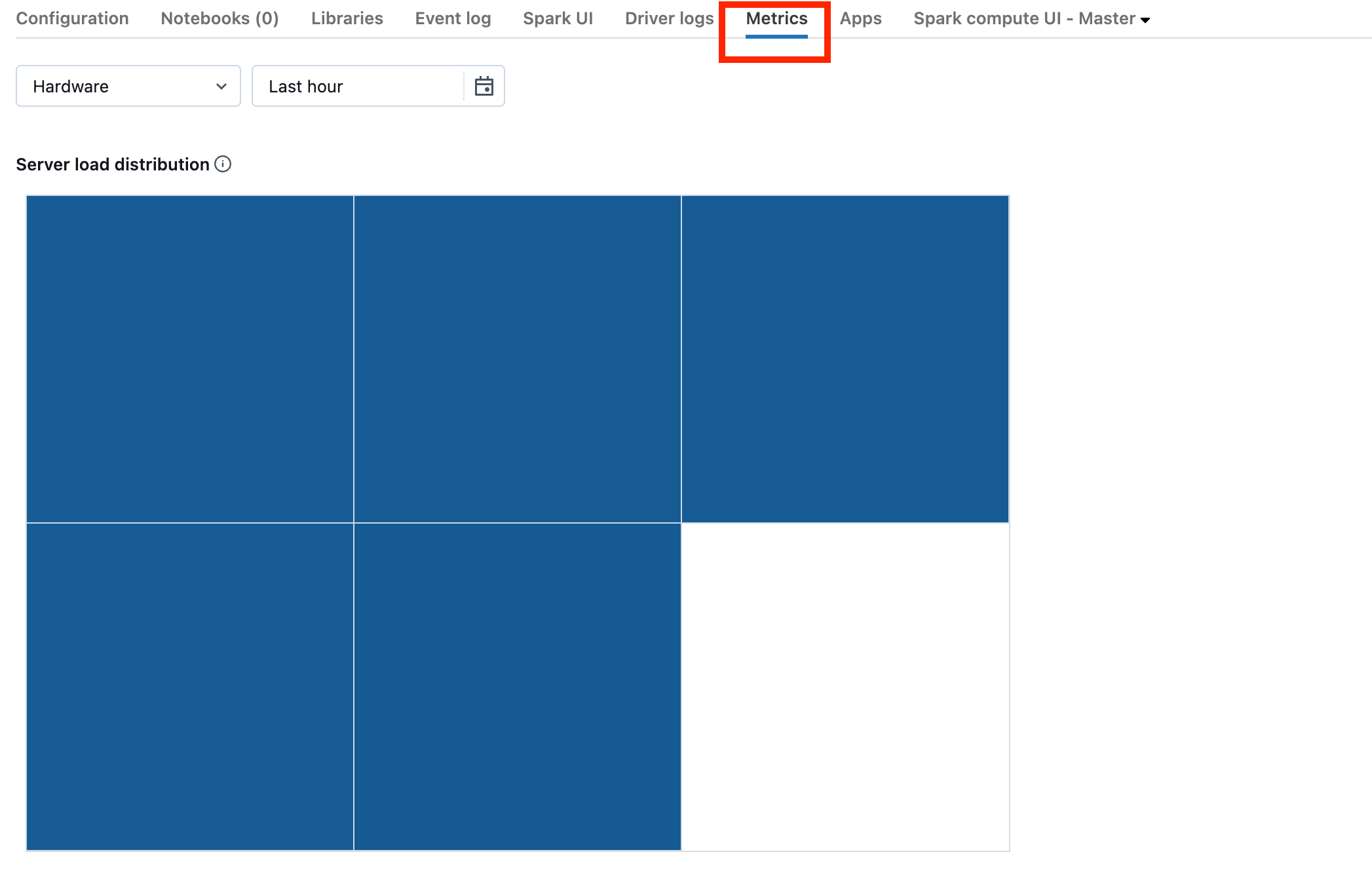
サーバーの負荷分散の視覚化に注目してください。ドライバーの負荷が高いかどうかを確認する必要があります。 この視覚化では、クラスター内の各マシンごとに色のブロックが表示されます。 赤は負荷が高いことを意味し、青はまったく負荷がかからないことを意味します。
前のスクリーンショットは、基本的にアイドル状態のクラスターを示しています。 ドライバーが過負荷になっている場合は、次のようになります。
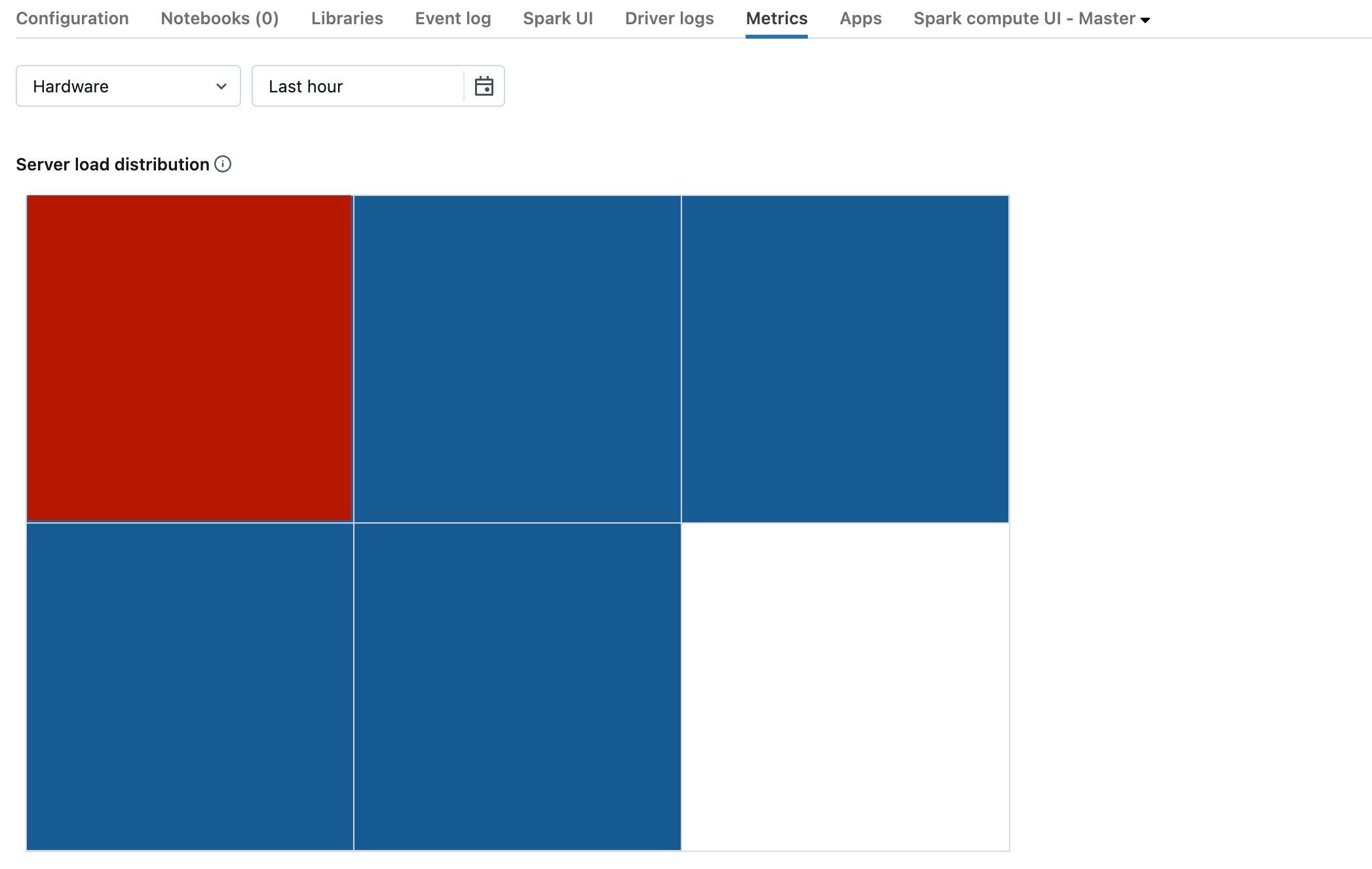
1つの正方形が赤で、他の正方形が青であることがわかります。 赤い四角の上にマウスを転がして、赤いブロックがドライバーを表していることを確認します。
過負荷になったドライバーを修正するには、 「Spark ドライバーの過負荷」を参照してください。
クラスターが故障しています
クラスターが故障することはまれですが、その場合、何が起こったのかを判断するのが困難になる可能性があります。 問題が解決するかどうかを確認するには、クラスターを再起動してください。 また、ログを調べて、疑わしいものがないかどうかを確認することもできます。 確認する場所は、以下のスクリーンショットで強調表示されている「イベント ログ」タブと「ドライバー ログ」タブです。
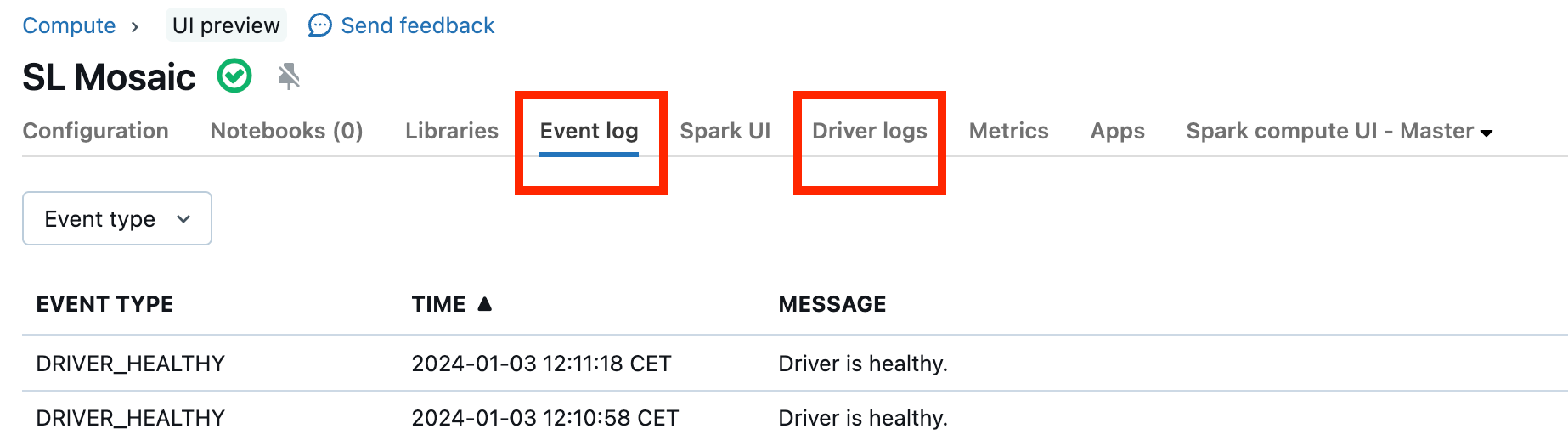
ワーカーのログにアクセスするには、 クラスター ログ配信を有効にする必要があります。 ログ レベルを変更することもできますが、Databricks アカウント チームに問い合わせてサポートを受ける必要がある場合があります。