Looker に接続する
この記事では、 Databricks クラスターまたは Databricks SQL ウェアハウス(以前の Databricks SQLエンドポイント)でLookerを使用する方法について説明します。
重要
永続的な派生テーブル(PDT)が有効になっている場合、デフォルトでは、Lookerは関連付けられたデータベースに接続して5分ごとにPDTを再生成します。 Databricks では、過剰なコンピュート コストが発生しないように、既定の頻度を変更することをお勧めします。 詳細については、「 永続的な派生テーブル (PDT) の有効化と管理」を参照してください。
要件
Lookerに手動で接続する前に、次のものが必要です。
Databricks ワークスペース内のクラスターまたは SQLウェアハウス。
クラスターまたは SQLウェアハウスの接続の詳細 (具体的には、 サーバーのホスト名、 ポート、 および HTTP パス の値)。
Databricks 個人用アクセストークン。個人用アクセストークンを作成するには、「ワークスペース ユーザー向けの個人用アクセストークンDatabricks」の手順に従います。
注
セキュリティのベスト プラクティスとして、自動化されたツール、システム、スクリプト、アプリを使用して認証する場合、 Databricksでは、ワークスペース ユーザーではなく、サービス プリンシパルに属する個人のアクセス トークンを使用することをお勧めします。 サービスプリンシパルのトークンを作成するには、 「サービスプリンシパルのトークンの管理」を参照してください。
Lookerに手動で接続する
Lookerに手動で接続するには、次の手順を実行します。
Lookerで、[管理者>接続] >[接続を追加]をクリックします。
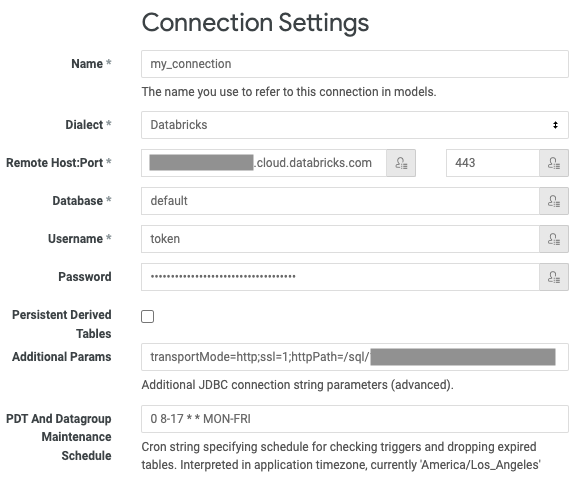
接続の一意の [名前 ] を入力します。
ヒント
接続名には、小文字、数字、アンダースコアのみを含める必要があります。 他の文字は受け入れられる可能性がありますが、後で予期しない結果が生じる可能性があります。
[ダイアレクト] で [Databricks] を選択します。
[リモート ホスト] に、要件から サーバー ホスト名 を入力します。
[ ポート] に、要件から [ポート ] を入力します。
[データベース] に、接続を介してアクセスするワークスペース内のデータベースの名前を入力します (
defaultなど)。[ユーザー名] に「
token」と入力します。[パスワード] に、要件から個人用アクセストークンを入力します。
[ 追加のパラメーター] に「
transportMode=http;ssl=1;httpPath=<http-path>」と入力し、<http-path>要件の HTTP パス 値に置き換えます。「PDTおよびデータグループメンテナンススケジュール」で、有効な
cron式を入力して、PDTを再生成するためのデフォルトの頻度を変更します。デフォルトの頻度は 5 分ごとです。クエリーを他のタイムゾーンに変換する場合は、 クエリータイムゾーンを調整します。
残りのフィールドについては、特にデフォルトのままにします。
最大接続 数 と 接続プールのタイムアウト をデフォルトのままにします。
[データベースのタイムゾーン] は空白のままにします (すべてを UTC で格納している場合)。
[ これらの設定のテスト] をクリックします。
テストが成功した場合は、[ 接続の追加] をクリックします。
Looker でデータベースをモデル化する
このセクションでは、プロジェクトを作成し、ジェネレーターを実行します。 次のステップ では、接続用のデータベースに永続的なテーブルが格納されていることを前提としています。
[ 開発 ] メニューの [ 開発モード] をオンにします。
[ 開発> LookMLプロジェクトの管理] をクリックします。
[ 新しいLookMLプロジェクト]をクリックします。
一意の プロジェクト名を入力します。
ヒント
プロジェクト名には、小文字、数字、アンダースコアのみを含める必要があります。 他の文字は受け入れられる可能性がありますが、後で予期しない結果が生じる可能性があります。
[接続] で、ステップ 2 から接続の名前を選択します。
[スキーマ] に「
default」と入力します (ただし、接続を介してモデル化する他のデータベースがある場合を除く)。残りのフィールドについては、特にデフォルトのままにします。
[ 開始点 ] を [ データベース スキーマからモデルを生成] に設定したままにします。
[ビルド ビュー] は [すべてのテーブル] に残します。
[ プロジェクトの作成] をクリックします。
プロジェクトを作成してジェネレータを実行すると、Lookerは1つの .model ファイルと複数の .view ファイルを含むユーザーインターフェイスを表示します。 .model ファイルには、スキーマ内のテーブルとそれらの間で検出された結合関係が表示され、 .view ファイルには、スキーマ内の各テーブルで使用できる各ディメンション (列) が一覧表示されます。
永続的な派生テーブル (PDT) の有効化と管理
Lookerは、 永続的な派生テーブル (PDT)を作成することで、クエリーの時間とデータベースの負荷を減らすことができます。 PDTは、Lookerがデータベースのスクラッチスキーマに書き込む派生テーブルです。 Looker 、指定したスケジュールで PDT を再生成します。 詳細については、Lookerドキュメントの 「永続的な派生テーブル(PDT)」 を参照してください。
データベース接続のPDTを有効にするには、その接続の 「永続派生テーブル 」を選択し、画面の指示を完了します。 詳細については、Lookerドキュメントの「 永続的な派生テーブル 」および 「PDTプロセス用の個別のログイン資格情報の構成 」を参照してください。
PDTが有効になっている場合、デフォルトでは、Lookerは関連付けられたデータベースに接続して5分ごとにPDTを再生成します。 Lookerは、関連付けられた Databricks リソースが停止している場合、そのリソースを再起動します。 Databricks では、データベース接続の [PDT とデータグループのメンテナンス スケジュール] フィールドを有効な cron 式に設定して、既定の頻度を変更することをお勧めします。 詳細については、Lookerドキュメントの 「PDTとデータグループのメンテナンススケジュール 」を参照してください。
PDTを有効にしたり、既存のデータベース接続のPDT再生成頻度を変更したりするには、「データベース接続>の管理」をクリックし、 データベース接続の横にある「 編集 」をクリックして、前述の手順に従います。