Depurar código usando o Databricks Connect para a extensão Databricks para Visual Studio Code
Este artigo descreve como depurar código usando a integração do Databricks Connect na extensão Databricks para Visual Studio Code. Consulte O que é a extensão Databricks para Visual Studio Code?.
Esta informação pressupõe que você já instalou e configurou a extensão Databricks para Visual Studio Code. Consulte Instalar a extensão Databricks para Visual Studio Code.
Observação
Este recurso é Experimental.
A integração do Databricks Connect na extensão do Databricks para o Visual Studio Code suporta apenas uma parte do padrão de autenticação unificada do cliente Databricks. Para obter mais informações, consulte Configuração de autenticação para a extensão Databricks para VS Code.
A extensão do Databricks para o Visual Studio Code inclui o Databricks Connect. O senhor pode usar Databricks Connect na extensão Databricks do Visual Studio Code para executar e fazer a depuração passo a passo de arquivos individuais Python (.py) e Python Jupyter Notebook (.ipynb). A extensão Databricks para o Visual Studio Code inclui Databricks Connect para Databricks Runtime 13.3 LTS e acima. Não há suporte para versões anteriores do Databricks Connect.
Requisitos
Antes de poder usar o Databricks Connect na extensão Databricks para Visual Studio Code, você deve primeiro atender aos requisitos do Databricks Connect. Esses requisitos incluem itens como um workspace habilitado com Unity Catalog, clusters executando o Databricks Runtime 13.0 ou superior e com um modo de acesso de clusters de usuário único ou compartilhado e uma versão local do Python instalada com suas versões principais e secundárias correspondentes às do Python. instalados nos clusters.
passo 1: Criar um ambiente virtual Python
Crie e ative um ambiente virtual Python para seu projeto de código Python. Os ambientes virtuais Python ajudam a garantir que o seu projeto de código utiliza versões compatíveis de pacotes Python e Python (neste caso, o pacote Databricks Connect). As instruções e exemplos neste artigo usam ambientes virtuais venv ou Poetry for Python. A Databricks não testou totalmente o pacote Databricks Connect com outros tipos de ambientes virtuais Python, como o Conda.
Crie um ambiente virtual Python usando venv
No terminal do Visual Studio Code (view > Terminal) definido como o diretório raiz do seu projeto de código Python, instrua
venva usar Python para o ambiente virtual e, em seguida, crie os arquivos de suporte do ambiente virtual em um diretório oculto chamado.venvno diretório raiz do seu projeto de código Python, executando o seguinte comando:# Linux and macOS python3.10 -m venv ./.venv # Windows python3.10 -m venv .\.venv
O comando anterior utiliza Python 3.10, que corresponde à versão principal e secundária do Python que o Databricks Runtime 13.0 utiliza. Certifique-se de usar a versão principal e secundária do Python que corresponda à versão instalada do Python em seus clusters .
Se o Visual Studio Code exibir a mensagem “Percebemos que um novo ambiente foi criado. Deseja selecioná-lo para a pasta workspace ?” clique em Sim.
Use
venvpara ativar o ambiente virtual. Consulte a documentação do venv para saber o comando correto a ser usado, com base no seu sistema operacional e tipo de terminal. Por exemplo, no macOS executandozsh:source ./.venv/bin/activate
Você saberá que seu ambiente virtual está ativado quando o nome do ambiente virtual (por exemplo,
.venv) for exibido entre parênteses logo antes do prompt do terminal.Para desativar o ambiente virtual a qualquer momento, execute o comando
deactivate.Você saberá que seu ambiente virtual está desativado quando o nome do ambiente virtual não for mais exibido entre parênteses antes do prompt do terminal.
Vá para a etapa 2: Atualize seu código Python para estabelecer um contexto de depuração.
Crie um ambiente virtual Python usando Poetry
Instale Poetry, se ainda não o fez.
No terminal do Visual Studio Code (view > Terminal) definido como o diretório raiz do seu projeto de código Python existente, instrua
poetrypara inicializar seu projeto de código Python para Poetry, executando o seguinte comando:poetry initPoetry exibe vários prompts para você completar. Nenhum desses prompts é específico da extensão Databricks para Visual Studio Code ou do Databricks Connect. Para obter informações sobre esses prompts, consulte init.
Depois de concluir as solicitações, o Poetry adiciona um arquivo
pyproject.tomlao seu projeto Python. Para obter informações sobre o arquivopyproject.toml, consulte O arquivo pyproject.toml.Com o terminal do Visual Studio Code ainda definido como o diretório raiz do seu projeto de código Python, instrua
poetrypara ler o arquivopyproject.toml, resolver as dependências e instalá-las, criar um arquivopoetry.lockpara bloquear as dependências e, finalmente, para criar um ambiente virtual. Para fazer isso, execute o seguinte comando:poetry installInstrua o Visual Studio Code para usar o interpretador Python incluído no ambiente virtual deste projeto Python, da seguinte maneira:
Encontre o caminho completo para o interpretador Python que está no ambiente virtual deste projeto Python, executando o seguinte comando no diretório raiz do projeto:
poetry env info
Copie o caminho completo exibido na saída do campo
Virtualenv > Executable, por exemplo, o caminho completo que contémpypoetry/virtualenvs.Na Paleta de Comandos (view > Paleta de Comandos), insira o comando
>Python: Select Interpreter.Insira o caminho completo para o interpretador Python que você acabou de copiar.
Com o terminal do Visual Studio Code ainda definido como o diretório raiz do seu projeto de código Python, instrua
poetrypara ativar o ambiente virtual e entrar no shell. Para fazer isso, execute o seguinte comando:poetry shellVocê saberá que seu ambiente virtual está ativado e o shell foi inserido quando o nome do ambiente virtual for exibido entre parênteses, logo antes do prompt do terminal.
Para desativar o ambiente virtual e sair do shell a qualquer momento, execute o comando
exit.Você saberá que saiu do shell quando o nome do ambiente virtual não for mais exibido entre parênteses logo antes do prompt do terminal.
Para obter mais informações sobre como criar e gerenciar ambientes virtuais do Poetry, consulte Gerenciando ambientes.
passo 2: atualize seu código Python para estabelecer um contexto de depuração
Para estabelecer um contexto de depuração entre o Databricks Connect e os seus clusters, o seu código Python deve inicializar a classe DatabricksSession chamando DatabricksSession.builder.getOrCreate().
Observe que você não precisa especificar configurações como o nome da instância do seu workspace , um access token ou o ID e o número da porta dos seus clustersao inicializar a classe DatabricksSession. O Databricks Connect obtém essas informações dos detalhes de configuração que você já forneceu por meio da extensão Databricks para Visual Studio Code anteriormente neste artigo.
Para obter informações adicionais sobre a inicialização da classe DatabricksSession , consulte os exemplos de código do Databricks Connect.
Importante
Se você usar a extensão Databricks para Visual Studio Code para definir o tipo de autenticação como access tokenpessoal, a extensão definirá uma variável de ambiente SPARK_REMOTE relacionada com configurações de contexto de depuração para uso pelo Databricks Connect. Essas configurações de contexto de depuração incluem o nome da instância workspace relacionado, access token pessoal e o ID clusters .
No Databricks Connect, você pode usar a classe DatabricksSession ou SparkSession juntamente com SPARK_REMOTE e autenticação access token pessoal para estabelecer de forma rápida e fácil o contexto de depuração de forma programática. Para outros tipos de autenticação do Databricks com suporte, você pode usar apenas a classe DatabricksSession para estabelecer o contexto de depuração.
Para obter mais informações, consulte Configurar o cliente na documentação do Databricks Connect.
passo 3: Habilitar Databricks Connect
Com a extensão aberta e a seção do workspace configurada para seu projeto de código, faça o seguinte:
Na barra de status do Visual Studio Code, clique no botão vermelho Databricks Connect desativado .
Se a secção clusters ainda não estiver configurada na extensão, aparece a seguinte mensagem: “Anexe um clusters para utilizar o Databricks Connect”. Clique em Anexar clusters e selecione um clusters que atenda aos requisitos do Databricks Connect.
Se a seção clusters estiver configurada, mas os clusters não forem compatíveis com o Databricks Connect, clique no botão vermelho Databricks Connect desativado , clique em Attach clusters e selecione clusters compatíveis.
Se o pacote Databricks Connect (e suas dependências) ainda não estiver instalado, a seguinte mensagem será exibida: “Para depuração interativa e preenchimento automático, você precisa do Databricks Connect. Gostaria de instalá-lo no ambiente
<environment-name>.” Clique em Instalar.Na barra de status do Visual Studio Code, o botão Databricks Connect ativado é exibido.
Se o botão vermelho Databricks Connect desativado ainda for exibido, clique nele e conclua as instruções na tela para que o botão Databricks Connect ativado seja exibido.
Depois que o botão de ativação do Databricks Connect for exibido, o senhor estará pronto para usar o Databricks Connect.
Observação
Não é necessário configurar a seção Destino de Sincronização da extensão para que seu projeto de código use o Databricks Connect.
Se você usar o Poetry, poderá sincronizar seus arquivos pyproject.toml e poetry.lock com o pacote Databricks Connect instalado (e suas dependências) executando o comando a seguir. Certifique-se de substituir 13.3.2 pela versão do pacote Databricks Connect que corresponde àquela que foi instalada pela extensão Databricks para Visual Studio Code para o seu projeto.
poetry add databricks-connect==13.3.2
passo 4: execução ou depuração do seu código Python
Depois de ativar o Databricks Connect para o seu projeto de código, execute ou depure o seu ficheiro Python ou Notebook da seguinte forma.
Observação
O procedimento a seguir usa a extensão Databricks para o Visual Studio Code, versão 1, que está disponível de forma geral. Para concluir este procedimento para a extensão Databricks para Visual Studio Code, versão 2, atualmente em Private Preview, pule para a execução ou depuração de seu código Python com a extensão Databricks para Visual Studio Code, versão 2.
Para executar ou depurar um arquivo Python (.py):
Em seu projeto de código, abra o arquivo Python que deseja executar ou depurar.
Defina quaisquer pontos de interrupção de depuração no arquivo Python.
Na barra de título do editor de arquivos, clique na seta suspensa ao lado do ícone de reprodução (execução ou depuração). Em seguida, na lista suspensa, selecione Debug Python File. Esta opção suporta depuração passo a passo, pontos de interrupção, expressões de observação, pilhas de chamadas e recursos semelhantes. Esta opção utiliza o Databricks Connect para executar o código Python localmente, executar o código PySpark nos clusters no workspace remoto e enviar respostas remotas de volta ao Visual Studio Code para depuração local.
Observação
Outras opções, que não suportam depuração, incluem:
execução Arquivo Python para usar o Databricks Connect para executar o arquivo ou Notebook, mas sem suporte de depuração. Essa escolha envia o arquivo para o workspace remoto, executa o código Python e PySpark do arquivo nos clusters remotos do workspace e envia a resposta remota para o Visual Studio Code Terminal.
upload e execute o arquivo no Databricks para enviar o arquivo para o workspace remoto, execute o código Python e PySpark do arquivo nos clusters remotos no workspace e envie a resposta remota para o terminal do Visual Studio Code. Esta escolha não utiliza o Databricks Connect.
arquivo de execução como fluxo de trabalho no Databricks para enviar o arquivo para o espaço de trabalho remoto, executar o código Python e PySpark do arquivo nos clusters associados a um Databricks Job automatizado e enviar os resultados para um editor no Visual Studio Code. Esta escolha não utiliza o Databricks Connect.
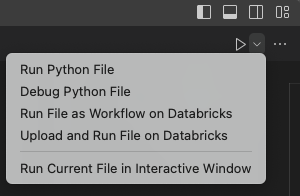
A opção de execução Arquivo Atual na Janela Interativa , se disponível, tenta executar o arquivo localmente em um editor interativo especial do Visual Studio Code. Databricks não recomenda esta opção.
Para executar ou depurar um Jupyter Notebook Python (.ipynb):
No seu projeto de código, abra o Python Jupyter Notebook que você deseja executar ou depurar. Certifique-se de que o arquivo Python esteja no formato Jupyter Notebook e tenha a extensão
.ipynb.Dica
Você pode criar um novo notebook Python Jupyter executando o comando >Create: New Jupyter Notebook na paleta de comandos.
Clique em execução Todas as Células para executar todas as células sem depuração, Executar Célula para executar uma célula correspondente individual sem depuração ou execução por Linha para executar uma célula individual linha por linha com depuração limitada, com valores de variáveis exibidos no painel Jupyter (view > Abrir view > Jupyter).
Para depuração completa em uma célula individual, defina pontos de interrupção e clique em Depurar célula no menu próximo ao botão de execução da célula.
Depois de clicar em qualquer uma dessas opções, você poderá ser solicitado a instalar as dependências ausentes do pacote Python Jupyter Notebook . Clique para instalar.
Para obter mais informações, consulte Jupyter Notebook no VS Code.
executar ou depurar seu código Python com a extensão Databricks para Visual Studio Code, versão 2
Observação
A extensão Databricks para Visual Studio Code, versão 2, está em Private Preview.
Este procedimento pressupõe o seguinte:
O senhor já instalou e configurou a extensão Databricks para o Visual Studio Code, versão 2. Consulte Instalar e abrir a extensão Databricks para o Visual Studio Code, versão 2.
O senhor já seguiu os passos 1-3 neste artigo.
Depois de ativar o Databricks Connect para o seu projeto de código, execute ou depure o seu ficheiro Python ou Notebook da seguinte forma.
Para executar ou depurar um arquivo Python (.py):
Em seu projeto de código, abra o arquivo Python que deseja executar ou depurar.
Defina quaisquer pontos de interrupção de depuração no arquivo Python.
No Explorer view, clique com o botão direito do mouse no arquivo
.pye, em seguida, clique em execução em Databricks > Databricks Connect: Debug current file. A saída aparece no painel Console de depuração.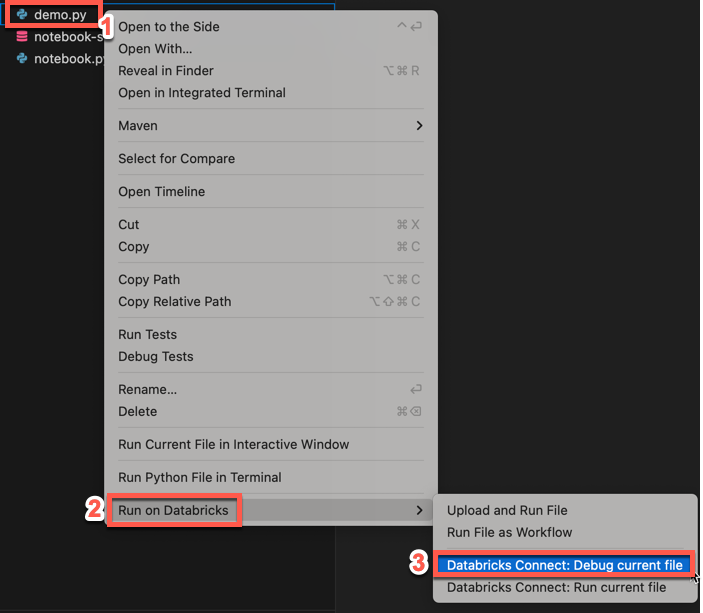
Dica
Outra maneira de fazer isso é clicar no ícone de execução no Databricks ao lado da lista da guia do editor e, em seguida, clicar em Databricks Connect: Debug current file (Depurar arquivo atual).
Para executar ou depurar um Jupyter Notebook Python (.ipynb):
No seu projeto de código, abra o Python Jupyter Notebook que você deseja executar ou depurar. Certifique-se de que o arquivo Python esteja no formato Jupyter Notebook e tenha a extensão
.ipynb.Dica
Você pode criar um novo notebook Python Jupyter executando o comando >Create: New Jupyter Notebook na paleta de comandos.
Clique em execução Todas as Células para executar todas as células sem depuração, Executar Célula para executar uma célula correspondente individual sem depuração ou execução por Linha para executar uma célula individual linha por linha com depuração limitada, com valores de variáveis exibidos no painel Jupyter (view > Abrir view > Jupyter).
Para depuração completa em uma célula individual, defina pontos de interrupção e clique em Depurar célula no menu próximo ao botão de execução da célula.
Depois de clicar em qualquer uma dessas opções, você poderá ser solicitado a instalar as dependências ausentes do pacote Python Jupyter Notebook . Clique para instalar.
Para obter mais informações, consulte Jupyter Notebook no VS Code.