Visual Studio Code の Databricks 拡張機能に対して Databricks Connect を使用してコードをデバッグする
この記事では、Visual Studio Code の Databricks 拡張機能で Databricks Connect 統合を使用してコードをデバッグする方法について説明します。 「Visual Studio Code の Databricks 拡張機能とは」を参照してください。
この情報では、Visual Studio Code 用の Databricks 拡張機能が既にインストールおよび設定されていることを前提としています。 「Visual Studio Code 用の Databricks 拡張機能のインストール」を参照してください。
注:
この機能は 実験的です。
Visual Studio Code の Databricks 拡張機能内の Databricks Connect 統合では 、Databricks クライアント統合認証標準の一部のみがサポートされます。 詳細については、 「VS Code のDatabricks拡張機能の認証設定」を参照してください。
Visual Studio Code の Databricks 拡張機能には、Databricks Connectが含まれています。 Visual Studio Code の Databricks 拡張機能内から Databricks Connect を使用して、個々の Python ( .py ) ファイルと Python Jupyter ノートブック ( .ipynb ) を実行し、ステップスルー デバッグを行うことができます。 Visual Studio Code の Databricks 拡張機能には、Databricks Runtime 13.3 LTS 以降用の Databricks Connect が含まれています。 Databricks Connect の以前のバージョンはサポートされていません。
要件
Visual Studio Code の Databricks 拡張機能内から Databricks Connect を使用するには、まず Databricks Connect の要件を満たす必要があります。 これらの要件には、Unity Catalog で有効になっているワークスペース、 Databricks Runtime 13.0 以降を実行し、クラスター アクセス モードがシングル ユーザーまたは共有のクラスター バージョン、クラスターにインストールされている Python のメジャー バージョンとマイナー バージョンと一致するローカル バージョンの Python がインストールされていることなどが含まれます。
ステップ 1: Python 仮想環境を作成する
Python コード プロジェクト用の Python 仮想環境 を作成してアクティブ化します。 Python 仮想環境は、コード プロジェクトで互換性のあるバージョンの Python と Python パッケージ (この場合は Databricks Connect パッケージ) を使用していることを確認するのに役立ちます。 この記事の手順と例では、Python 仮想環境に venv または Poetry を使用します。 Databricks では、Conda などの他の種類の Python 仮想環境で Databricks Connect パッケージを完全にテストしていません。
venvを使用して Python 仮想環境を作成する
Python コード プロジェクトのルート ディレクトリに設定された Visual Studio コード ターミナル (View > ターミナル) から、仮想環境に Python を使用するように
venv指示し、次のコマンドを実行して、Python コード プロジェクトのルート ディレクトリ内の.venvという名前の隠しディレクトリに仮想環境のサポート ファイルを作成します。# Linux and macOS python3.10 -m venv ./.venv # Windows python3.10 -m venv .\.venv
上記のコマンド は Python 3.10 を使用しており、これは Databricks Runtime 13.0 で使用されている Python のメジャー バージョンとマイナー バージョンと一致します。 クラスターにインストールされている Python のバージョンと一致する Python のメジャー バージョンとマイナー バージョンを必ず使用してください。
Visual Studio Code に "新しい環境が作成されたことに気付きました。 ワークスペース フォルダー用に選択しますか 」をクリックします。
venvを使用して仮想環境をアクティブ化します。オペレーティングシステムとターミナルごとに使用すべき正しいコマンドについては、venvドキュメントを参照してください。例えば、zshを実行しているmacOSでは、以下のようになります。source ./.venv/bin/activate
ターミナルプロンプトの直前に仮想環境の名前が括弧内に表示されると(例:
.venv)、仮想環境がアクティブ化されたことが分かります。任意のタイミングで仮想環境を非アクティブ化するには、
deactivateのコマンドを実行します。ターミナルプロンプトの直前に仮想環境の名前が括弧内に表示されなくなると、仮想環境が非アクティブ化されたことが分かります。
「ステップ 2: Python コードを更新してデバッグ コンテキストを確立する」に進んでください。
Poetry を使って Python 仮想環境を作成する
既存の Python コード プロジェクトのルート ディレクトリに設定された Visual Studio コード ターミナル (View > ターミナル) から、次のコマンドを実行して、Poetry 用に Python コード プロジェクトを初期化するように
poetryに指示します。poetry initPoetry はあなたが完了するようにいくつかのプロンプトを表示します。 これらのプロンプトはいずれも、Visual Studio Code の Databricks 拡張機能または Databricks Connect に固有のものではありません。 これらのプロンプトに関する情報については、 init のマニュアルページを参照してください。
プロンプトを完了すると、Poetry によって Python プロジェクトに
pyproject.tomlファイルが追加されます。pyproject.tomlファイルの詳細については、pyproject.toml ファイルを参照してください。Visual Studio Code ターミナルを Python コード プロジェクトのルート ディレクトリに設定した状態で、
pyproject.tomlファイルを読み取り、依存関係を解決してインストールし、依存関係をロックするpoetry.lockファイルを作成し、最後に仮想環境を作成するようにpoetryに指示します。これを行うには、次のコマンドを実行します。poetry install次のように、この Python プロジェクトの仮想環境に含まれている Python インタープリターを使用するように Visual Studio Code に指示します。
プロジェクトのルート ディレクトリから次のコマンドを実行して、この Python プロジェクトの仮想環境にある Python インタープリターへの完全パスを見つけます。
poetry env info
Virtualenv > Executableフィールドの出力に表示される絶対パス (例えば、pypoetry/virtualenvsを含む絶対パス) をコピーします。コマンド パレット ([コマンド パレットの表示]>) で、コマンド
>Python: Select Interpreterを入力します。コピーした Python インタープリターへの完全パスを入力します。
Visual Studio コード ターミナルを Python コード プロジェクトのルート ディレクトリに設定した状態で、仮想環境をアクティブ化してシェルに入るように
poetryに指示します。 これを行うには、次のコマンドを実行します。poetry shell仮想環境がアクティブ化され、ターミナルプロンプトの直前に仮想環境の名前が括弧内に表示されると、シェルが入力されることがわかります。
仮想環境を非アクティブ化してシェルを終了するには、次のコマンドを実行します
exit。仮想環境の名前がターミナルプロンプトの直前に括弧内に表示されなくなったときに、シェルを終了したことがわかります。
Poetry 仮想環境の作成と管理の詳細については、「 環境の管理」を参照してください。
ステップ 2: Python コードを更新してデバッグ コンテキストを確立する
Databricks Connect とクラスターの間にデバッグ コンテキストを確立するには、Python コードで DatabricksSession.builder.getOrCreate()を呼び出して DatabricksSession クラスを初期化する必要があります。
DatabricksSession クラスを初期化するときに、ワークスペースのインスタンス名、アクセス トークン、クラスターの ID とポート番号などの設定を指定する必要はありません。Databricks Connect は、この記事の前半で既に Visual Studio Code 用の Databricks 拡張機能を通じて既に指定した構成の詳細から、この情報を取得します。
DatabricksSession クラスの初期化に関する追加情報については、Databricks Connect のコード例を参照してください。
重要:
Visual Studio Code の Databricks 拡張機能を使用して認証の種類を personal アクセストークンに設定した場合、拡張機能は、Databricks Connect で使用するデバッグ コンテキスト設定を使用して、関連する SPARK_REMOTE 環境変数を設定します。 これらのデバッグ コンテキスト設定には、関連するワークスペース インスタンス名、個人用アクセストークン、およびクラスター ID が含まれます。
Databricks Connect では、 DatabricksSession または SparkSession クラスを SPARK_REMOTE および個人用アクセストークン認証と共に使用して、プログラムによってデバッグ コンテキストをすばやく簡単に確立できます。 サポートされているその他の Databricks 認証の種類については、 DatabricksSession クラスのみを使用してデバッグ コンテキストを確立できます。
詳細については、Databricks Connect ドキュメントの「 クライアントの設定 」を参照してください。
ステップ 3: Databricks 接続を有効にする
拡張機能を開き、コード プロジェクト用に [ワークスペース ] セクションを構成したら、次の操作を行います。
Visual Studio のコード ステータス バーで、赤い Databricks [接続が無効] ボタンをクリックします。
拡張機能で [クラスター ] セクションがまだ構成されていない場合は、"Databricks Connect を使用するようにクラスターをアタッチしてください" というメッセージが表示されます。 [ クラスターの接続] をクリックし、Databricks Connect の要件を満たすクラスターを選択します。
[クラスター] セクションが構成されているが、クラスターが Databricks Connect と互換性がない場合は、赤い Databricks Connect 無効 ボタンをクリックし、[クラスター のアタッチ] をクリックして、互換性のあるクラスターを選択します。
Databricks Connect パッケージ (およびその依存関係) がまだインストールされていない場合は、"対話型のデバッグとオートコンプリートには Databricks Connect が必要です。
<environment-name>環境にインストールしますか?「 インストール」をクリックします。Visual Studio Code ステータス バーに、 [Databricks Connect が有効になりました] ボタンが表示されます。
赤いDatabricks Connect 無効化ボタンがまだ表示される場合は、それをクリックし、画面上の指示に従ってDatabricks Connect 有効化ボタンを表示します。
[Databricks Connect が有効になりました]ボタンが表示されたら、Databricks Connect を使用する準備が整いました。
注:
コード プロジェクトで Databricks Connect を使用するために、拡張機能の [同期先 ] セクションを構成する必要はありません。
Poetry を使用する場合は、次のコマンドを実行して、 pyproject.toml ファイルと poetry.lock ファイルを、インストールされている Databricks Connect パッケージ (およびその依存関係) と同期できます。 13.3.2、プロジェクトの Visual Studio Code 用の Databricks 拡張機能によってインストールされたものと一致するバージョンの Databricks Connect パッケージに置き換えてください。
poetry add databricks-connect==13.3.2
ステップ 4: Python コードを実行またはデバッグする
コード プロジェクトに対して Databricks Connect を有効にした後、次のように Python ファイルまたはノートブックを実行またはデバッグします。
注:
次の手順では、一般公開されている Visual Studio Code の Databricks 拡張機能バージョン 1 を使用します。 現在プライベート プレビュー段階にある Visual Studio Code バージョン 2 の Databricks 拡張機能のこの手順を完了するには、「Visual Studio Code バージョン 2 の Databricks 拡張機能を使用して Python コードを実行またはデバッグする」に進んでください。
Python (.py) ファイルを実行またはデバッグするには:
コード プロジェクトで、実行またはデバッグする Python ファイルを開きます。
Python ファイル内にデバッグブレークポイントを設定します。
ファイル エディターのタイトル バーで、再生 ([実行] または [デバッグ]) アイコンの横にあるドロップダウン矢印をクリックします。 次に、ドロップダウン リストで [ Python ファイルのデバッグ] を選択します。 この選択により、ステップ スルー デバッグ、ブレークポイント、ウォッチ式、呼び出し履歴、および同様の機能がサポートされます。 この選択では、Databricks Connect を使用して Python コードをローカルで実行し、リモート ワークスペースのクラスターで PySpark コードを実行し、ローカル デバッグのためにリモート応答を Visual Studio Code に送り返します。
注:
デバッグをサポートしないその他の選択肢には、次のものがあります。
実行 Databricks Connect を使用してファイルまたはノートブックを実行するための Python ファイルですが、デバッグはサポートされていません。 この選択により、ファイルがリモート ワークスペースに送信され、ワークスペース内のリモート クラスターでファイルの Python および PySpark コードが実行され、リモート応答が Visual Studio コード ターミナルに送信されます。
Databricks でファイルをアップロードして実行 してファイルをリモート ワークスペースに送信し、ワークスペース内のリモート クラスターでファイルの Python および PySpark コードを実行し、リモート応答を Visual Studio Code ターミナルに送信します。 この選択では、 Databricks Connectは使用されません。
実行 ファイルをリモート ワークスペースに送信し、自動化された Databricks ジョブに関連付けられているクラスターでファイルの Python および PySpark コードを実行し、結果を Visual Studio Code のエディターに送信するには、Databricks 上のワークフローとしてファイル を実行します。この選択では、 Databricks Connectは使用されません。
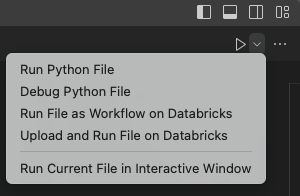
[ 対話型ウィンドウで現在のファイルを実行する ] オプションが使用可能な場合、特別な Visual Studio Code 対話型エディターでファイルをローカルに実行しようとします。 Databricks では、このオプションはお勧めしません。
Python Jupyter ノートブックを実行またはデバッグするには (.ipynb):
コード プロジェクトで、実行またはデバッグする Python Jupyter ノートブックを開きます。 Python ファイルが Jupyter ノートブック形式であり、拡張子が
.ipynbであることを確認します。ヒント
新しい Python Jupyter ノートブックを作成するには、 コマンド パレット 内から >作成: 新しい Jupyter ノートブック コマンドを実行します。
デバッグなしですべてのセルを実行するには 「すべてのセルを実行」 を、デバッグなしで対応する個々のセルを実行するには「セルを実行」 」を、 Jupyter パネルに変数値を表示して、デバッグを制限して個々のセルを行ごとに実行する >> 、「行ごとに実行」をクリックします。
個々のセル内で完全なデバッグを行うには、ブレークポイントを設定し、セルの [実行] ボタンの横にあるメニューの [セルのデバッグ] をクリックします。
これらのオプションのいずれかをクリックすると、不足している Python Jupyter ノートブック パッケージの依存関係をインストールするように求められる場合があります。 クリックしてインストールします。
詳細については、「 VS Code での Jupyter ノートブック」を参照してください。
Visual Studio Code バージョン 2 の Databricks 拡張機能を使用して Python コードを実行またはデバッグする
注:
Visual Studio Code の Databricks 拡張機能バージョン 2 は、プライベート プレビュー段階にあります。
この手順では、次のことを前提としています。
Visual Studio Code バージョン 2 の Databricks 拡張機能はすでにインストールされ、セットアップされています 。「 Visual Studio Code バージョン 2 の Databricks 拡張機能をインストールして開く」を参照してください。
この記事のステップ 1 ~ 3 はすでにフォロー済みです。
コード プロジェクトに対して Databricks Connect を有効にした後、次のように Python ファイルまたはノートブックを実行またはデバッグします。
Python (.py) ファイルを実行またはデバッグするには:
コード プロジェクトで、実行またはデバッグする Python ファイルを開きます。
Python ファイル内にデバッグブレークポイントを設定します。
エクスプローラービューで、
.pyファイルを右クリックし、 [Databricks で実行] > [Databricks Connect: 現在のファイルをデバッグ]をクリックします。 出力が [デバッグ コンソール ] ウィンドウに表示されます。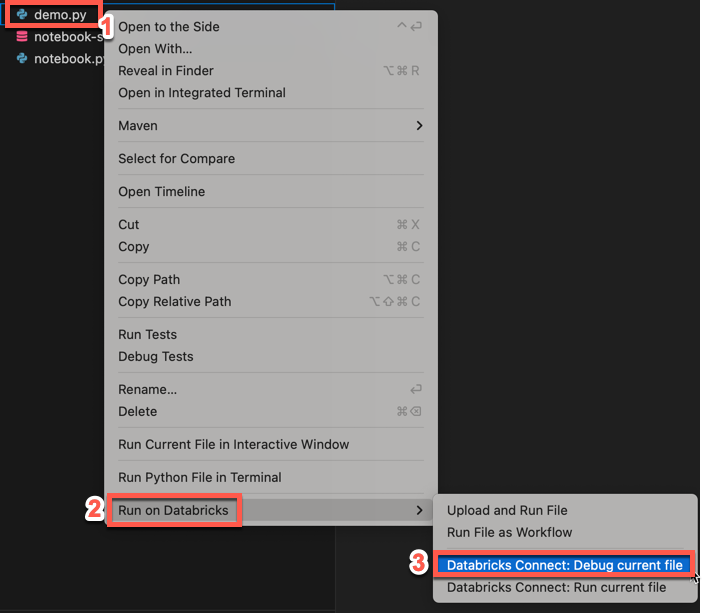
ヒント
これを行うもう 1 つの方法は、エディター タブのリストの横にあるDatabricks の実行アイコンをクリックし、 [Databricks Connect: Debug current file]をクリックすることです。
Python Jupyter ノートブックを実行またはデバッグするには (.ipynb):
コード プロジェクトで、実行またはデバッグする Python Jupyter ノートブックを開きます。 Python ファイルが Jupyter ノートブック形式であり、拡張子が
.ipynbであることを確認します。ヒント
新しい Python Jupyter ノートブックを作成するには、 コマンド パレット 内から >作成: 新しい Jupyter ノートブック コマンドを実行します。
デバッグなしですべてのセルを実行するには 「すべてのセルを実行」 を、デバッグなしで対応する個々のセルを実行するには「セルを実行」 」を、 Jupyter パネルに変数値を表示して、デバッグを制限して個々のセルを行ごとに実行する >> 、「行ごとに実行」をクリックします。
個々のセル内で完全なデバッグを行うには、ブレークポイントを設定し、セルの [実行] ボタンの横にあるメニューの [セルのデバッグ] をクリックします。
これらのオプションのいずれかをクリックすると、不足している Python Jupyter ノートブック パッケージの依存関係をインストールするように求められる場合があります。 クリックしてインストールします。
詳細については、「 VS Code での Jupyter ノートブック」を参照してください。