ノートブックの出力と結果
ノートブックを クラスターにアタッチ し、 1 つ以上のセルを実行すると、ノートブックに状態があり、出力が表示されます。 このセクションでは、ノートブックの状態と出力を管理する方法について説明します。
ノートブックの状態と出力をクリアする
ノートブックの状態と出力をクリアするには、実行メニューの下部にある クリアオプションのいずれかを選択します。
メニューオプション |
説明 |
|---|---|
すべてのセル出力をクリアする |
セル出力をクリアします。 これは、ノートブックを共有し、結果を含めたくない場合に便利です。 |
クリア状態 |
関数と変数の定義、データ、インポートされたライブラリを含むノートブックの状態をクリアします。 |
クリア状態と出力 |
セル出力とノートブックの状態をクリアします。 |
状態をクリアしてすべて実行する |
ノートブックの状態をクリアし、新しい実行を開始します。 |
結果テーブル
セルが実行されると、結果が結果テーブルに表示されます。 結果テーブルでは、次の操作を実行できます。
列または表形式の結果データの他のサブセットをクリップボードにコピーします。
結果テーブルに対してテキスト検索を実行します。
表のセル間を移動するには、キーボードの矢印キーを使用します。
列名またはセル値の一部をダブルクリックしてドラッグし、目的のテキストを選択します。
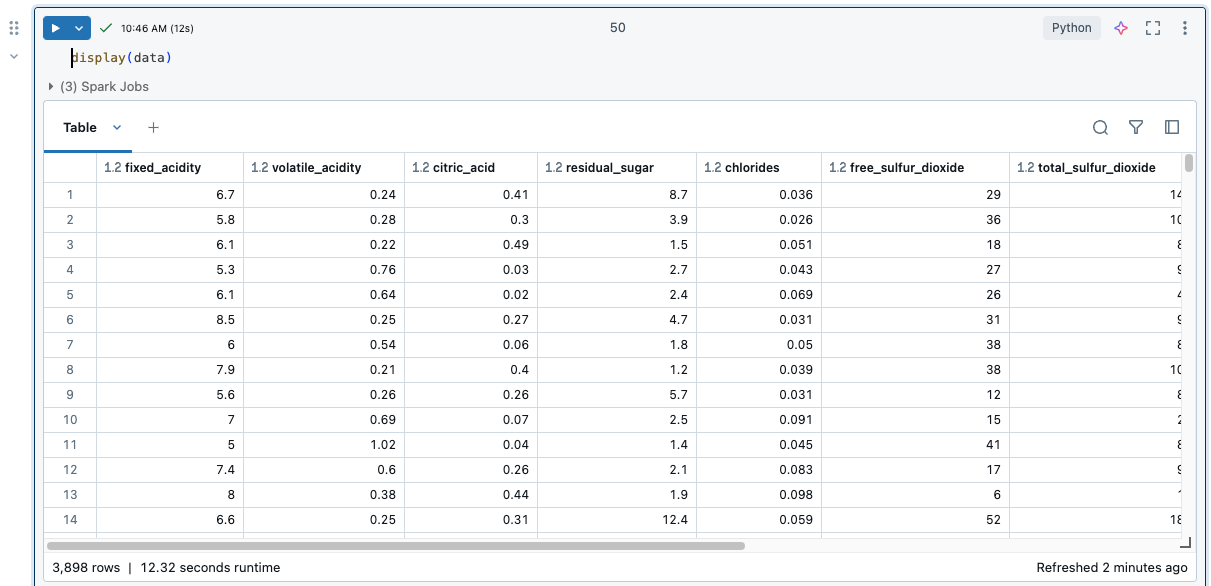
結果テーブルの制限を表示するには、 ノートブックの結果テーブルの制限を参照してください。
データの選択
結果テーブルでデータを選択するには、次のいずれかの操作を行います。
列または行のヘッダーをクリックします。
テーブルの左上のセルをクリックして、テーブル全体を選択します。
任意のセルのセットにカーソルをドラッグして選択します。
選択情報を表示するサイドパネルを開くには、パネルアイコンをクリックします![]() 検索ボックスの横、右上隅にあるアイコンをクリックします。
検索ボックスの横、右上隅にあるアイコンをクリックします。
データをクリップボードにコピーする
選択したデータをクリップボードにコピーするには、MacOSの場合は Cmd + c を、Windowsの場合は Ctrl + c を押すか、右クリックしてドロップダウンメニューから [コピー ]を選択します。 [ 名前を付けてコピー ] を選択して、選択したデータを CSV、TSV、または Markdown 形式でコピーすることもできます。
結果のソート
結果テーブルを列の値で並べ替えるには、列名の上にカーソルを置きます。 列名を含むアイコンがセルの右側に表示されます。 矢印をクリックして列を並べ替えます。
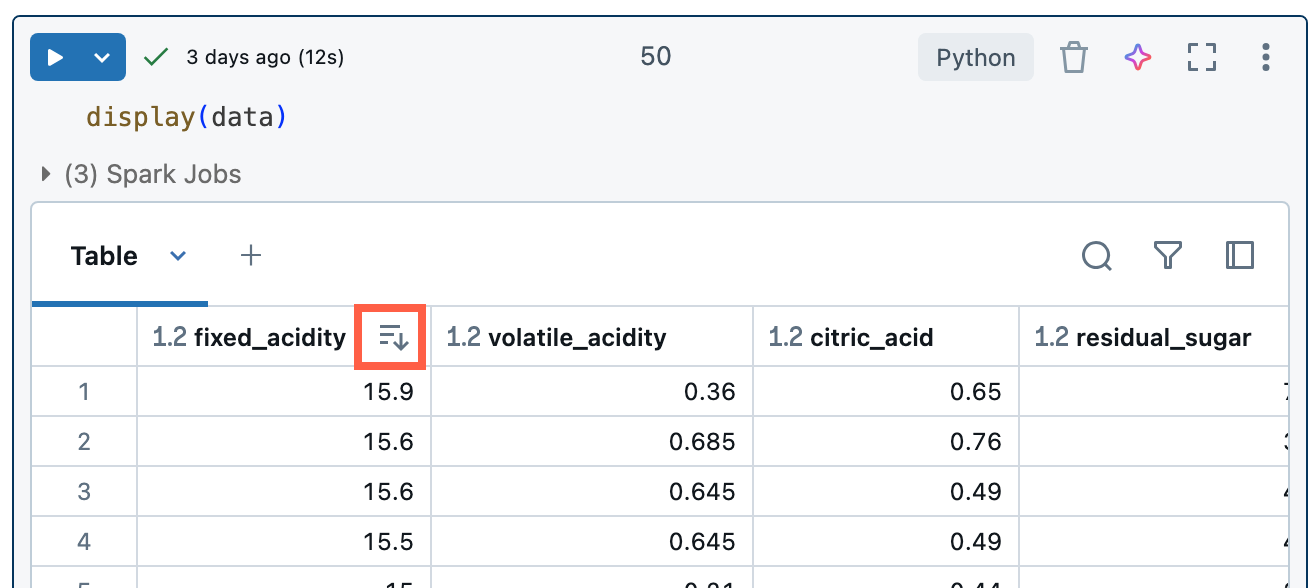
複数の列で並べ替えるには、 Shift キーを押しながら列の並べ替え矢印をクリックします。
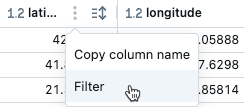
結果をフィルタリングする
フィルターを作成するには、いくつかの方法があります。
セル結果の右上にある [
 ] をクリックします。 表示されるダイアログで、フィルタリングする列と、適用するフィルタールールと値を選択します。 例えば:
] をクリックします。 表示されるダイアログで、フィルタリングする列と、適用するフィルタールールと値を選択します。 例えば: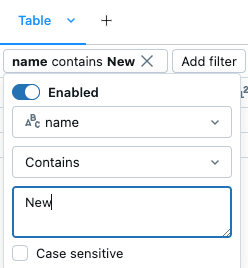
別のフィルタを追加するには、
![[フィルターの追加] ボタン](../_images/add-filter.png) をクリックします。
をクリックします。フィルターを一時的に有効または無効にするには、ダイアログの 有効/無効 ボタンを切り替えます。 フィルタを削除するには、フィルタ名
 の横にある [X] をクリックします。
の横にある [X] をクリックします。特定の値でフィルタリングするには、その値を持つセルを右クリックし、ドロップダウンメニューからこの値でフィルタリングを選択します。
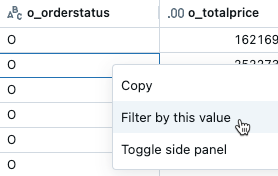
特定の列でフィルタリングするには、列名でケバブメニューを使用します。
デフォルトでは、フィルタは結果テーブルに表示される結果にのみ適用されます。 返されるデータが切り捨てられる場合 (たとえば、クエリが 10,000 行を超える行を返す場合や、データセットが 2 MB を超える場合)、フィルターは返された行にのみ適用されます。 表の右上にあるメモは、切り捨てられたデータにフィルターが適用されたことを示しています。
代わりに、データセット全体をフィルタリングすることもできます。 [切り捨てられたデータ] をクリックし、[完全なデータセット] を選択します。データセットのサイズによっては、フィルターの適用に時間がかかる場合があります。

 データ型を示します。 インジケーターにカーソルを合わせると、データ型が表示されます。
データ型を示します。 インジケーターにカーソルを合わせると、データ型が表示されます。
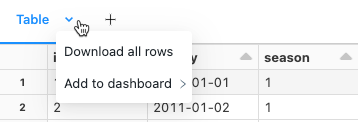
ダウンロード結果
デフォルトでは、結果のダウンロードが有効になっています。 この設定を切り替えるには、 ノートブックから結果をダウンロードする機能を管理するを参照してください。
表形式の出力を含むセル結果をローカル コンピューターにダウンロードできます。 タブタイトルの横にある下向きの矢印をクリックします。 メニュー オプションは、結果の行数と Databricks Runtime のバージョンによって異なります。 ダウンロードした結果は、ノートブック名に対応する名前の CSV ファイルとしてローカル マシンに保存されます。
SQLウェアハウスに接続されているノートブックの場合、結果をExcelファイルとしてダウンロードすることもできます。

SQL セルの結果を調べる
Databricks ノートブックでは、SQL 言語セルの結果は、変数 _sqldfに割り当てられた DataFrame として自動的に使用できます。 _sqldf変数を使用して、後続の Python セルと SQL セルで前の SQL 出力を参照できます。詳細については、 SQL セルの結果の調査を参照してください。
セルごとに複数の出力を表示する
Python ノートブックと Python 以外のノートブックの %python セルでは、セルごとに複数の出力がサポートされます。 たとえば、次のコードの出力には、プロットとテーブルの両方が含まれます。
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)

ノートブックの出力を Databricks Git フォルダーにコミットする
.ipynb のコミットについて学習するには ノートブック出力については、.ipynb ノートブック出力のコミットを許可するを参照してください。
ノートブックは.ipynbである必要があります ファイル
ワークスペース管理者設定では、ノートブックの出力をコミットできるようにする必要があります